Loki
Loki 是 Grafana Labs 推出的日志聚合系统,常和 Grafana、Grafana Alloy、Fluent Bit 或 Vector 一起组成日志观测方案。它的设计目标不是全文索引所有日志内容,而是通过 label 索引日志流,再按时间范围读取日志内容。
Abstract
Loki 的核心定位是“像 Prometheus 一样处理日志”:用 label 定位日志流,用查询语言 LogQL 检索和聚合日志。
实践中需要重点关注:
- Loki 只索引 label,不默认索引完整日志内容
- label 应该低基数,避免把 request id、user id、trace id 等高基数字段放进 label
- 日志采集通常由 Grafana Alloy、Fluent Bit 或 Vector 完成;Promtail 已 EOL,不建议新部署
- Grafana 负责查询、展示和告警
- 生产环境要关注日志保留周期、存储后端、限流、查询性能和 label 设计
背景
传统日志系统常见做法是对日志内容建立全文索引,查询灵活但存储和索引成本较高。Loki 选择了另一条路线:
- 只对 label 建立索引
- 日志正文按时间切分后写入对象存储或本地文件系统
- 查询时先通过 label 找到日志流,再扫描对应时间范围内的日志内容
Loki 的核心思路
- 用 label 定位服务、实例、环境、命名空间等维度
- 用日志正文保存具体事件内容
- 用 LogQL 做过滤、解析和聚合
- 用 Grafana 提供可视化查询和告警
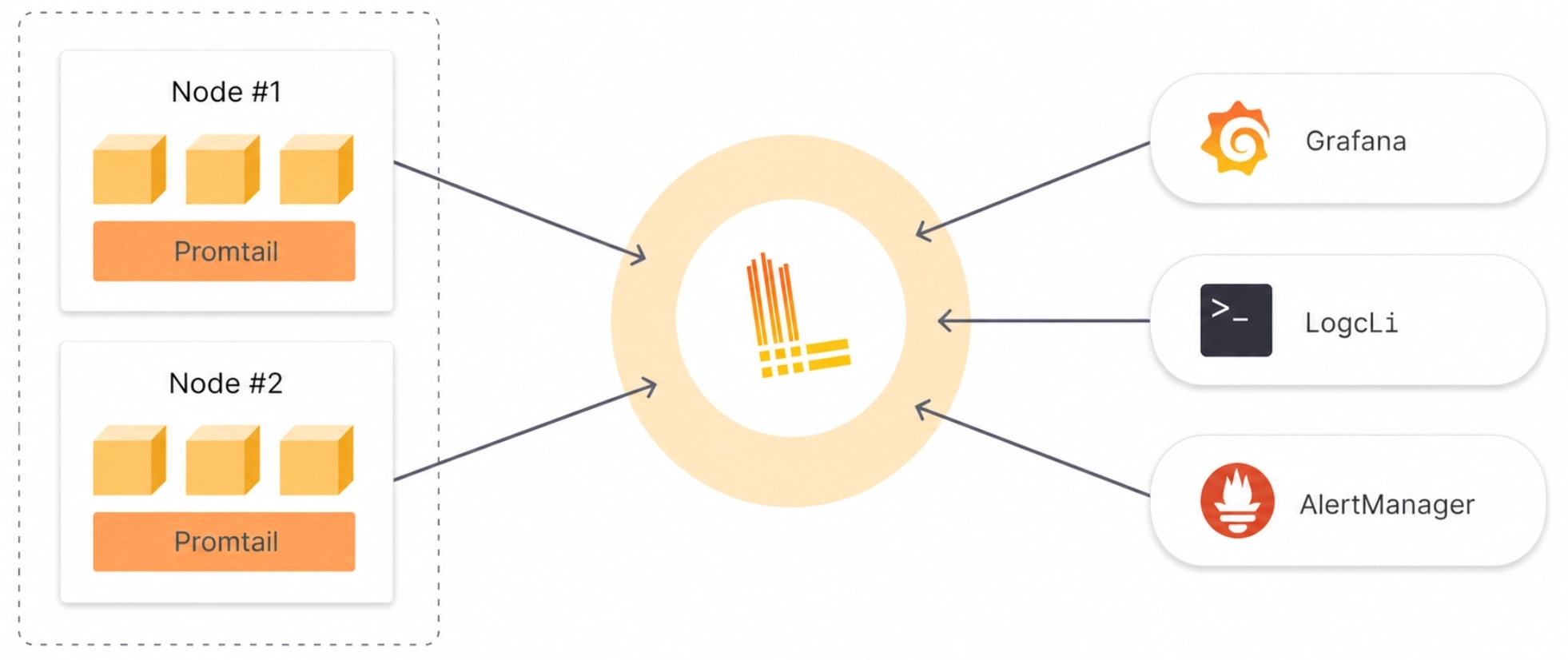
核心组件
一个完整的 Loki 日志方案通常由日志采集、日志存储、查询语言和可视化入口组成:
- Loki:接收、存储和查询日志
- Alloy / Fluent Bit / Vector:采集日志并推送到 Loki
- Grafana:查询、展示和告警
- Object Storage:存储日志块,如 S3、GCS、MinIO
- LogQL:Loki 的查询语言,用于过滤、解析和聚合日志
Promtail 与 Alloy
Promtail 是 Loki 早期常用的日志采集 Agent,但它已在 2026-03-02 进入 EOL,不再提供后续支持或更新。新系统应优先使用 Grafana Alloy、Fluent Bit 或 Vector;已有 Promtail 部署也应规划迁移到 Alloy 或其他受支持的采集器。
基本架构
flowchart LR
App[Application Logs] --> Agent[Alloy / Fluent Bit / Vector]
Agent -->|Push logs| Loki[Loki]
Loki <-->|Read / Write chunks| Storage[(Object Storage)]
User[User] --> Grafana
Grafana[Grafana] -->|LogQL Query| Loki一次典型日志链路:
- 应用把日志写到 stdout、文件或容器日志目录
- Alloy、Fluent Bit 或 Vector 作为采集 Agent 读取日志,并附加 label
- Agent 将日志推送到 Loki
- Loki 根据 label 和时间组织索引,并将日志块写入存储后端
- 用户在 Grafana 中编写 LogQL
- Grafana 将 LogQL 查询发送给 Loki,并展示查询结果
Label 模型
Loki 的 label 类似 Prometheus label,用来描述一组日志流。
常见 label:
job:采集任务或服务名app:应用名称env:环境,如dev、staging、prodnamespace:Kubernetes namespacepod:Kubernetes Pod 名称container:容器名称level:日志级别,如info、warn、error
控制 label 基数
不要把高基数字段放进 label,例如:
request_idtrace_iduser_idorder_id- 完整 URL
- 错误堆栈
高基数 label 会导致日志流数量爆炸,增加索引、写入和查询压力。此类字段应该留在日志正文中,在查询时通过 LogQL 过滤或解析。
LogQL
LogQL 是 Loki 的查询语言,语法风格接近 PromQL,但面向日志流。
基础查询
查询某个应用的所有日志:
{app="api"}
查询生产环境中 api 应用的错误日志:
{env="prod", app="api"} |= "error"
排除健康检查日志:
{app="api"} != "/health"
JSON 解析
如果日志是 JSON 格式,可以用 json 解析字段:
{app="api"} | json | level="error"
按字段过滤:
{app="api"} | json | status >= 500
聚合查询
统计 5 分钟内错误日志数量:
count_over_time({app="api"} |= "error" [5m])
按应用统计错误日志数量:
sum by (app) (
count_over_time({env="prod"} |= "error" [5m])
)
Kubernetes 采集
在 Kubernetes 中,应用通常把日志写到容器标准输出。容器运行时会把 stdout / stderr 写入节点上的容器日志文件,采集 Agent 再以 DaemonSet 形式运行在每个节点上读取这些文件,并附加 namespace、pod、container 等 label。
常见采集链路:
flowchart LR
Pod[Pod stdout / stderr] --> File[Node container log file]
File --> Agent[Alloy / Fluent Bit / Vector]
Agent -->|Push logs with labels| Loki[Loki]
Loki <-->|Read / Write chunks| Storage[(Object Storage)]
Grafana[Grafana] -->|LogQL Query| Loki常见 label 有 cluster、namespace、app、pod、container、node。
Kubernetes 中的 label 设计
Kubernetes 元数据很多,但不应该全部变成 Loki label。一般只保留稳定、低基数、查询时经常使用的字段,例如 cluster、namespace、app、container。Pod 名称可用于定位问题,但在高规模集群中也需要关注基数。
Loki vs Elasticsearch
| 对比项 | Loki | Elasticsearch |
|---|---|---|
| 索引方式 | 主要索引 label | 可全文索引日志内容 |
| 存储成本 | 通常较低 | 通常较高 |
| 查询方式 | 先按 label 定位日志流,再过滤正文 | 可直接全文检索 |
| 适用场景 | 云原生日志、服务日志、Kubernetes 日志 | 复杂全文搜索、日志分析、审计检索 |
| 运维复杂度 | 相对较低 | 集群和索引管理复杂度较高 |
选择建议:
- 如果日志主要按服务、环境、namespace、pod 等维度查询,Loki 很合适
- 如果需要大量全文搜索、复杂字段索引和审计检索,Elasticsearch 更合适
- Loki 更适合和 Prometheus / Grafana 观测体系集成
生产实践清单
- Label 设计:只把低基数、常用查询维度放进 label
- 日志格式:应用日志优先使用 JSON,便于 LogQL 解析字段
- 日志级别:统一
debug、info、warn、error等级 - 保留周期:根据成本和排障需求设置 retention
- 存储后端:生产环境优先使用对象存储
- 限流保护:配置写入速率、查询长度、返回行数等限制
- 多租户:需要隔离时启用 tenant,并规划认证方式
- 告警规则:基于错误日志数量、关键字和服务维度配置告警
- 日志脱敏:避免写入密码、Token、身份证、手机号等敏感信息
- Trace 关联:日志正文中保留
trace_id,但不要放进 label
常见排障方向
查不到日志
- Agent 是否正常运行
- Agent 是否有权限读取日志文件
- Loki URL 是否配置正确
- label 选择器是否过窄
- 查询时间范围是否正确
日志延迟较高
- Agent 是否有发送积压
- Loki ingester 是否过载
- 对象存储写入是否变慢
- 是否存在突发大流量日志
- 限流配置是否过低
查询很慢
- 查询时间范围是否过大
- label 选择器是否太宽
- 是否在大量日志正文上做复杂过滤
- 是否缺少常用低基数 label
- Loki 查询并发和资源是否不足
写入被拒绝
- 是否超过 ingestion rate limit
- 日志时间戳是否太旧
- 单行日志是否过大
- label 数量或 label value 是否超过限制
- tenant 配置是否正确
存储增长过快
- 日志级别是否过低,例如生产大量
debug - 是否有异常循环打印日志
- retention 是否过长
- 是否采集了不必要的 namespace 或容器
- 是否需要在 Agent 侧丢弃无价值日志