K-近邻算法(KNN)
Abstract
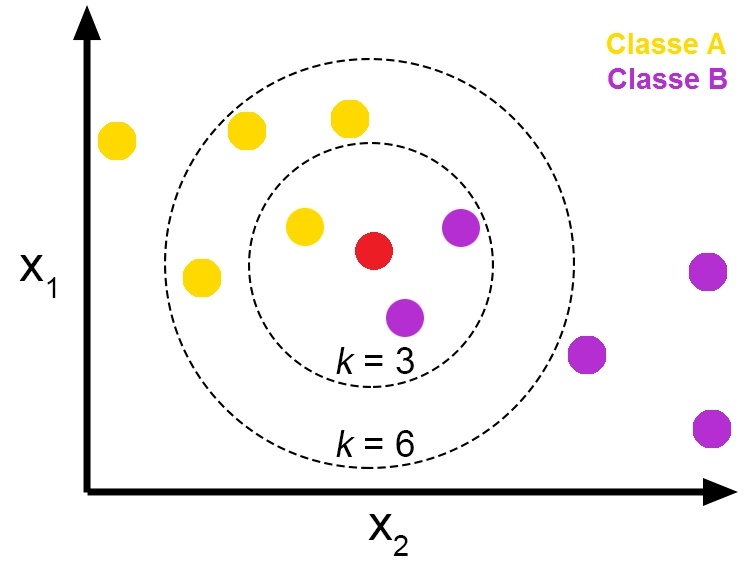
K 近邻(K-Nearest Neighbors, KNN)是一种 基于实例的监督学习算法,用于分类(Classification)和回归(Regression)。
- 分类任务:多数投票原则(近邻中出现最多的类别作为预测类别)。
- 回归任务:K 个近邻的均值或加权平均值作为预测值。
KNN 的基本思想是:一个数据点的类别或数值由它最近的 K 个邻居决定。
核心思想
KNN 是一种懒惰学习(Lazy Learning)算法,它不在训练阶段构建模型,而是在预测时才进行计算:
- 存储:将所有训练数据保存在内存中
- 计算距离:对于新样本,计算它与所有训练样本之间的距离
- 选邻居:选出距离最近的 K 个样本
- 投票/平均:
- 分类任务:K 个邻居中出现次数最多的类别作为预测结果(多数投票)
- 回归任务:K 个邻居的目标值的平均值作为预测结果
距离度量
计算新数据点与训练数据集中每个样本的距离。常见的距离计算方式:
欧氏距离
欧氏距离(Euclidean Distance)是最常用的距离度量,表示两点之间的直线距离:
\[
d(x, y) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2}
\]
曼哈顿距离
曼哈顿距离(Manhattan Distance)是沿坐标轴方向的距离之和,也称为"城市街区距离":
\[
d(x, y) = \sum_{i=1}^{n} |x_i - y_i|
\]
闵可夫斯基距离
闵可夫斯基距离(Minkowski Distance)是欧氏距离和曼哈顿距离的推广形式:
\[
d(x, y) = \left( \sum_{i=1}^{n} |x_i - y_i|^p \right)^{\frac{1}{p}}
\]
- 当 \(p=1\) 时,即曼哈顿距离
- 当 \(p=2\) 时,即欧氏距离
余弦相似度
余弦相似度(Cosine Similarity)衡量两个向量方向上的相似程度,常用于文本分类等高维稀疏场景:
\[
\text{cos}(\theta) = \frac{x \cdot y}{\|x\| \cdot \|y\|}
\]
K 值选择
K 值的选择直接影响模型的性能:
-
K 值过小
- 模型复杂度高,容易受噪声影响
- 容易过拟合(Overfitting)
- 决策边界不平滑
-
K 值过大
- 模型过于简单,忽略局部信息
- 容易欠拟合(Underfitting)
- 决策边界过于平滑
如何选择 K
- 通常通过交叉验证(Cross-Validation)选择最佳 K 值
- 经验法则:\(K = \sqrt{N}\)(N 为训练样本数量)
- K 一般选奇数,避免投票时出现平局
算法流程
flowchart TD
A[输入新样本] --> B[计算与所有训练样本的距离]
B --> C[按距离排序]
C --> D[选取最近的 K 个邻居]
D --> E{任务类型}
E -->|分类| F[多数投票,取出现最多的类别]
E -->|回归| G[取 K 个邻居目标值的平均值]
F --> H[输出预测结果]
G --> H数据预处理
KNN 对数据的尺度非常敏感,因为它依赖距离计算。特征归一化是使用 KNN 前的必要步骤。
Min-Max Normalization
最小-最大归一化(Min-Max Normalization)将特征缩放到 \([0, 1]\) 范围:
\[
x' = \frac{x - x_{\min}}{x_{\max} - x_{\min}}
\]
Z-Score Standardization
标准化(Z-Score Standardization)将特征转换为均值为 0、标准差为 1 的分布:
\[
x' = \frac{x - \mu}{\sigma}
\]
加权 KNN
在基本 KNN 中,K 个邻居的投票权重相同。加权 KNN(Weighted KNN)根据距离赋予不同权重,距离越近的邻居权重越大:
\[
w_i = \frac{1}{d(x, x_i)^2}
\]
加权投票
加权投票可以减少远处邻居的干扰,提高分类精度。
优缺点
-
优点
- 简单直观,易于理解和实现
- 无需训练过程(懒惰学习)
- 适用于多分类问题
- 对异常值有一定的鲁棒性(当 K 较大时)
-
缺点
- 计算开销大:预测时需遍历所有训练样本
- 存储开销大:需要保存全部训练数据
- 维度灾难:高维空间中距离度量失效
- 对不平衡数据集敏感
- 需要特征归一化
索引结构加速
为了解决 KNN 在大数据量下的效率问题,可以使用空间索引结构加速最近邻搜索:
- KD-Tree:将空间递归地划分为子区域,加速搜索过程,时间复杂度从 \(O(N)\) 降低到 \(O(\log N)\)
- Ball Tree:适用于更高维度的数据
- 近似最近邻(ANN):在可接受的精度损失下大幅提升搜索速度
应用场景
| 应用领域 | 具体场景 |
|---|---|
| 推荐系统 | 基于用户/物品相似度的协同过滤 |
| 图像识别 | 手写数字识别(如 MNIST) |
| 文本分类 | 垃圾邮件检测、情感分析 |
| 医疗诊断 | 基于症状特征的疾病分类 |
| 异常检测 | 识别与正常样本距离较远的数据点 |
代码示例
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.3, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
knn = KNeighborsClassifier(n_neighbors=5, weights="distance")
knn.fit(X_train, y_train)
print(f"准确率: {knn.score(X_test, y_test):.4f}")
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor(n_neighbors=5, weights="distance")
knn_reg.fit(X_train, y_train)
print(f"R² 分数: {knn_reg.score(X_test, y_test):.4f}")
KNN vs 其他算法
| 比较项 | KNN | 决策树 | 朴素贝叶斯 |
|---|---|---|---|
| 学习方式 | 懒惰学习 | 积极学习 | 积极学习 |
| 训练速度 | 无需训练 | 较快 | 很快 |
| 预测速度 | 慢(需遍历数据) | 快 | 快 |
| 可解释性 | 较好(基于邻居) | 很好(规则清晰) | 较好(概率模型) |
| 高维数据 | 表现差(维度灾难) | 表现尚可 | 表现较好 |