Transformer
Abstract
Transformer 是一种以 Attention 机制 为核心的序列建模架构,最早由论文 Attention Is All You Need 系统提出。它不再像 RNN 那样按时间步逐个传递信息,而是让序列中的每个位置都可以直接与其他位置建立联系,从而更高效地建模长距离依赖,并显著提升训练时的并行能力。
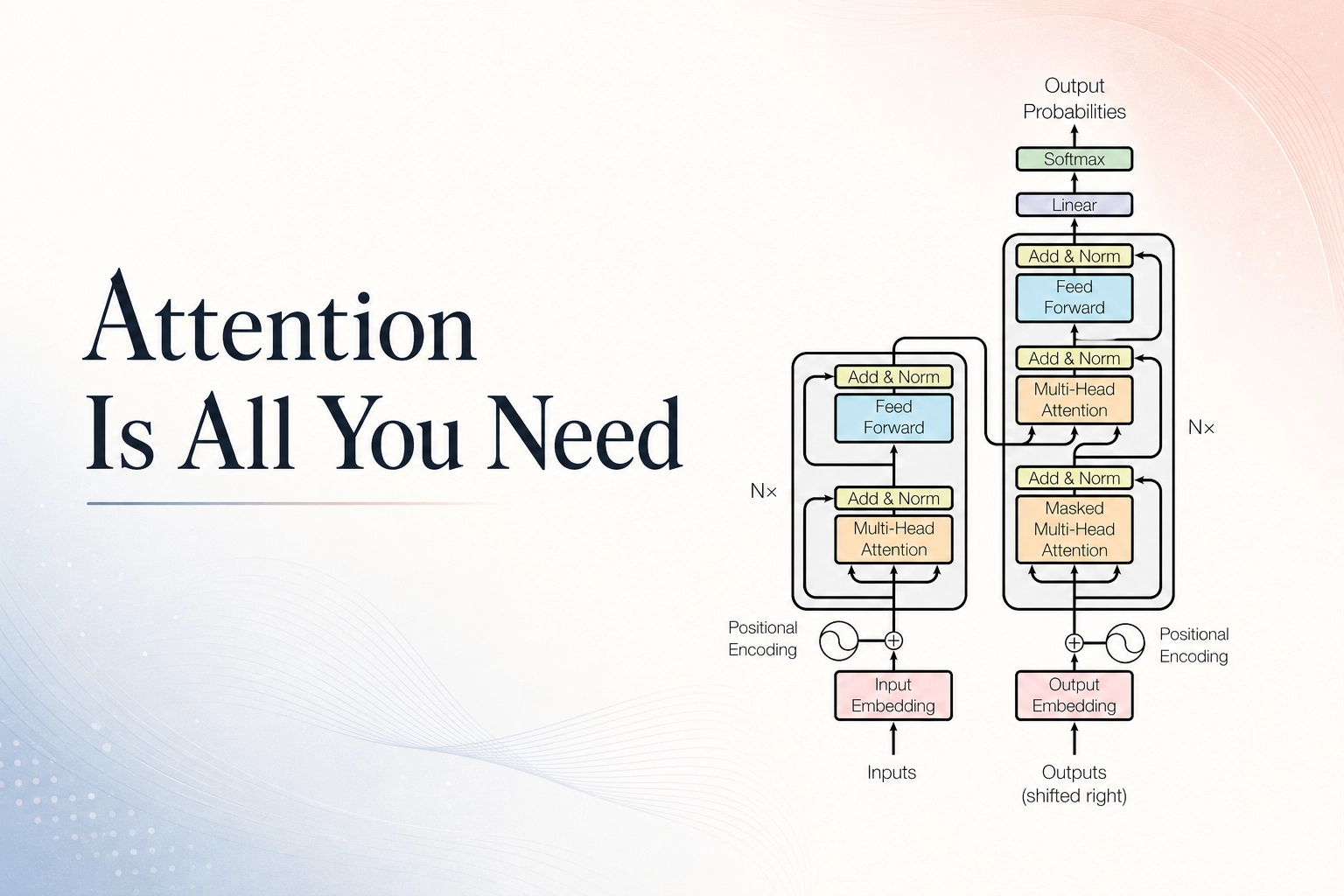
Transformer 的核心思想
Transformer 可以理解为一套“基于注意力的信息路由机制”:
- 用 Self-Attention 计算 token 之间应该互相参考多少
- 用 Multi-Head Attention 在多个表示子空间里捕捉不同类型的关系
- 用 Positional Encoding 弥补模型本身没有顺序感的问题
- 用 Encoder-Decoder 结构把输入理解和输出生成组织起来
背景
在 Transformer 之前,序列任务通常依赖 RNN、LSTM、GRU。 这类模型虽然能够处理变长序列,但有几个明显问题:
- 信息需要沿时间步逐步传递,长距离依赖路径很长
- 训练时难以充分并行
- 序列越长,梯度传播和建模难度越大
例如,在机器翻译里,句首的词有时会直接影响句尾的生成结果。如果模型必须一层一层、一步一步把信息传过去,学习会变得很吃力。
Transformer 的思路是:让每个位置都可以直接看到其他位置,把“距离远近”从时间路径问题转成一次 attention 计算。
常用的符号约定
为了方便说明,下面默认:
- 序列长度为 \(n\)
- 模型维度为 \(d_{model}\)
- 单个 head 的 key/query 维度为 \(d_k\)
- 单个 head 的 value 维度为 \(d_v\)
整体结构
经典 Transformer 是一个标准的 Encoder-Decoder 架构。
- Encoder 负责把输入序列编码成上下文相关表示
- Decoder 负责基于已生成部分和 encoder 输出,逐步生成目标序列
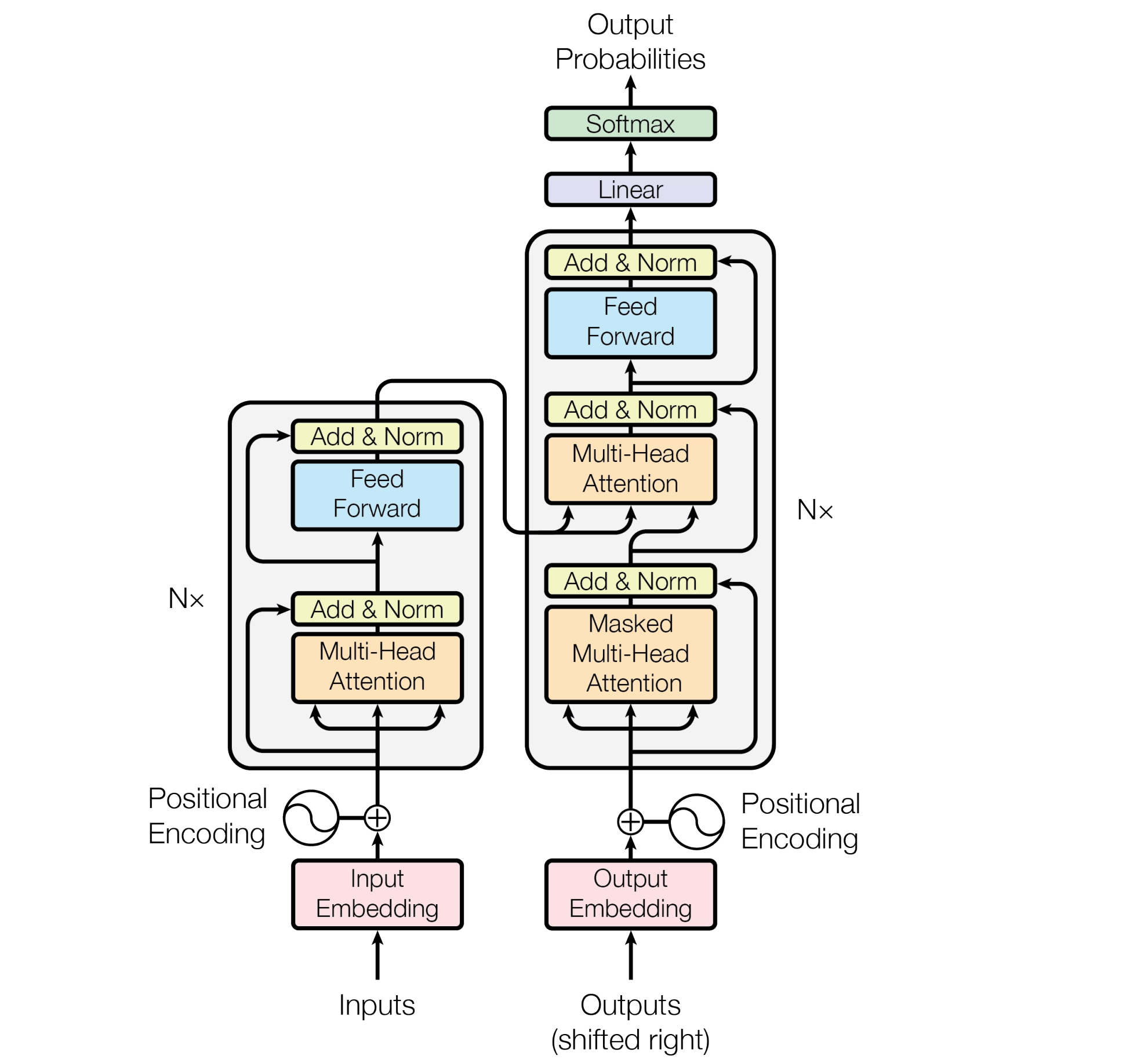
可以先把整体结构理解成下面两部分
- Encoder: 读懂输入序列,输出上下文化表示
- Decoder: 根据历史输出和输入表示,预测下一个 token
-
每个 Encoder Block 主要包含两层:
- Multi-Head Self-Attention
- Feed Forward Network
-
每个 Decoder Block 主要包含三层:
- Masked Multi-Head Self-Attention
- Encoder-Decoder Attention(Cross-Attention)
- Feed Forward Network
另外,每个子层外面都会包上 Residual Connection 和 Layer Normalization。
输入表示
Transformer 本身没有循环结构,也没有卷积结构,所以如果只把 token embedding 喂进去,模型并不知道谁在前、谁在后。
因此输入表示通常由两部分组成:
- Token Embedding:把 token 映射成稠密向量
- Positional Encoding:给每个位置注入位置信息
最终输入可以写成:
其中:
- \(E \in \mathbb{R}^{n \times d_{model}}\) 表示 token embedding
- \(P \in \mathbb{R}^{n \times d_{model}}\) 表示位置编码
- \(X \in \mathbb{R}^{n \times d_{model}}\) 是进入 encoder 的输入
Token Embedding
在自然语言任务中,模型不能直接处理文字本身。输入文本会先经过分词器,被切成一串 token;然后每个 token 会根据词表转换成一个整数编号;最后,embedding 层根据这些编号去一个可学习的矩阵中查表,取出对应的向量。
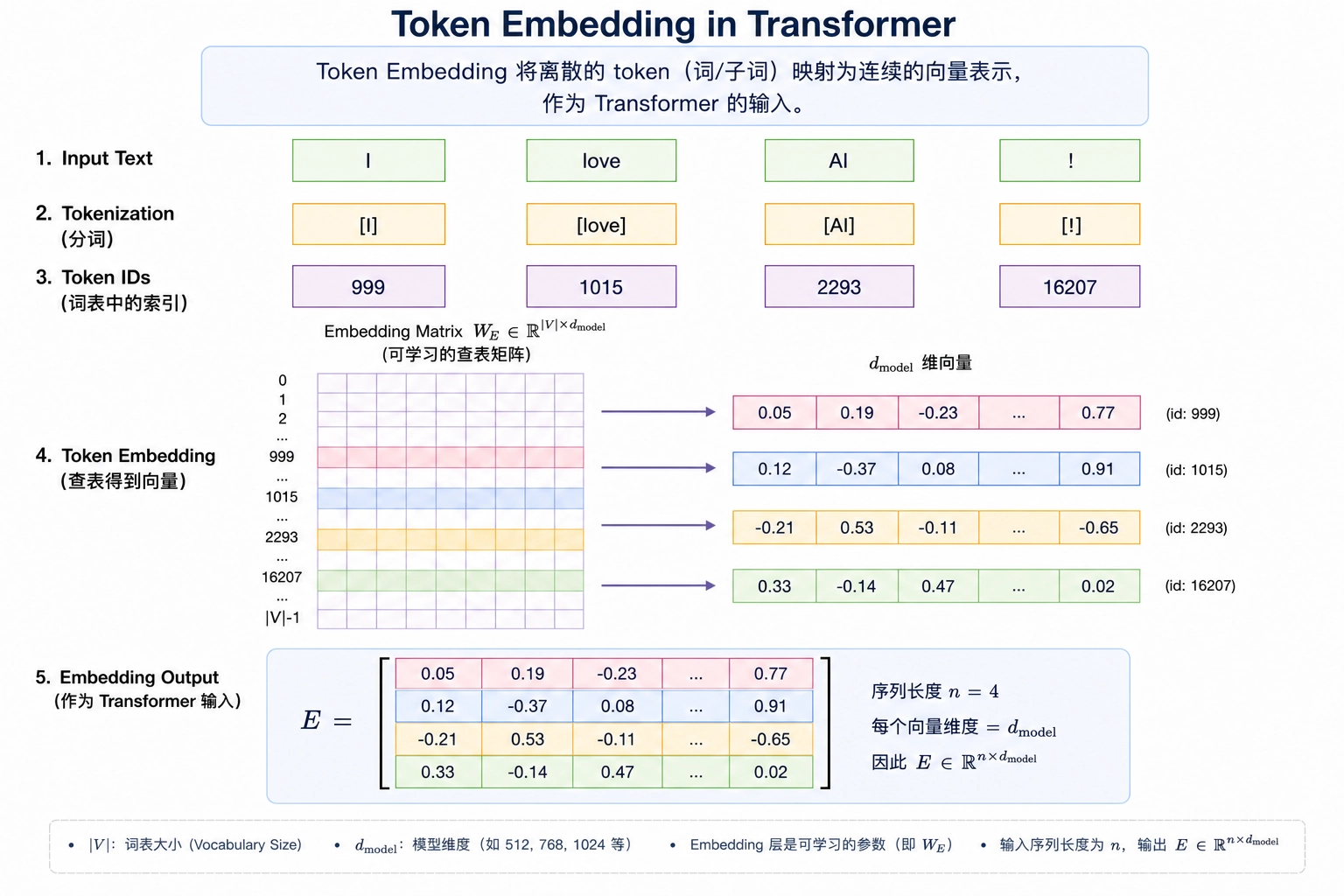
如果输入序列长度为 \(n\),那么分词之后可以得到 token id 序列:
Embedding 层会把每个离散的 token id 替换成一个 \(d_{model}\) 维向量。这样,原本无法直接计算的文本符号,就变成了 Transformer 可以处理的连续数值表示。
最终,整个 token id 序列会经过查找表,被表示成一个矩阵:
其中第 \(i\) 行就是第 \(i\) 个 token 的 embedding 向量。
查表矩阵
查表矩阵(embedding matrix)就是一个把离散 token ID 映射成连续向量表示的可学习参数表,通常作为模型权重的一部分,在开源模型中一般公开、在商业闭源模型中通常不公开。
其中:
- \(|V|\) 表示词表大小
- \(d_{model}\) 表示每个 token 向量的维度
Token embedding 是模型学习语义表示的起点。训练过程中,语义相近、用法相近的 token,通常会被更新到向量空间中相对接近的位置。
为什么要缩放
经典 Transformer 论文中,还会在加入位置编码之前对 embedding 做一次缩放:
这样做的目的是让 token embedding 的数值尺度更稳定,避免它在和位置编码相加时过小。
Positional Encoding
Self-Attention 会同时比较序列中的所有 token,但它本身并不包含“第几个位置”的概念。也就是说,模型能通过 token embedding 知道某个位置上是什么 token,却不能仅凭 token embedding 判断这个 token 出现在句首、句中还是句尾。
Positional Encoding 的作用
Positional Encoding 的作用是给序列中的每个位置生成一个和 token embedding 同维度的位置向量:
然后把它加到 token embedding 上:
这样进入 Transformer 的输入 \(X\) 同时包含两类信息:
- \(E\):这个位置上的 token 是什么
- \(P\):这个 token 出现在序列的哪个位置
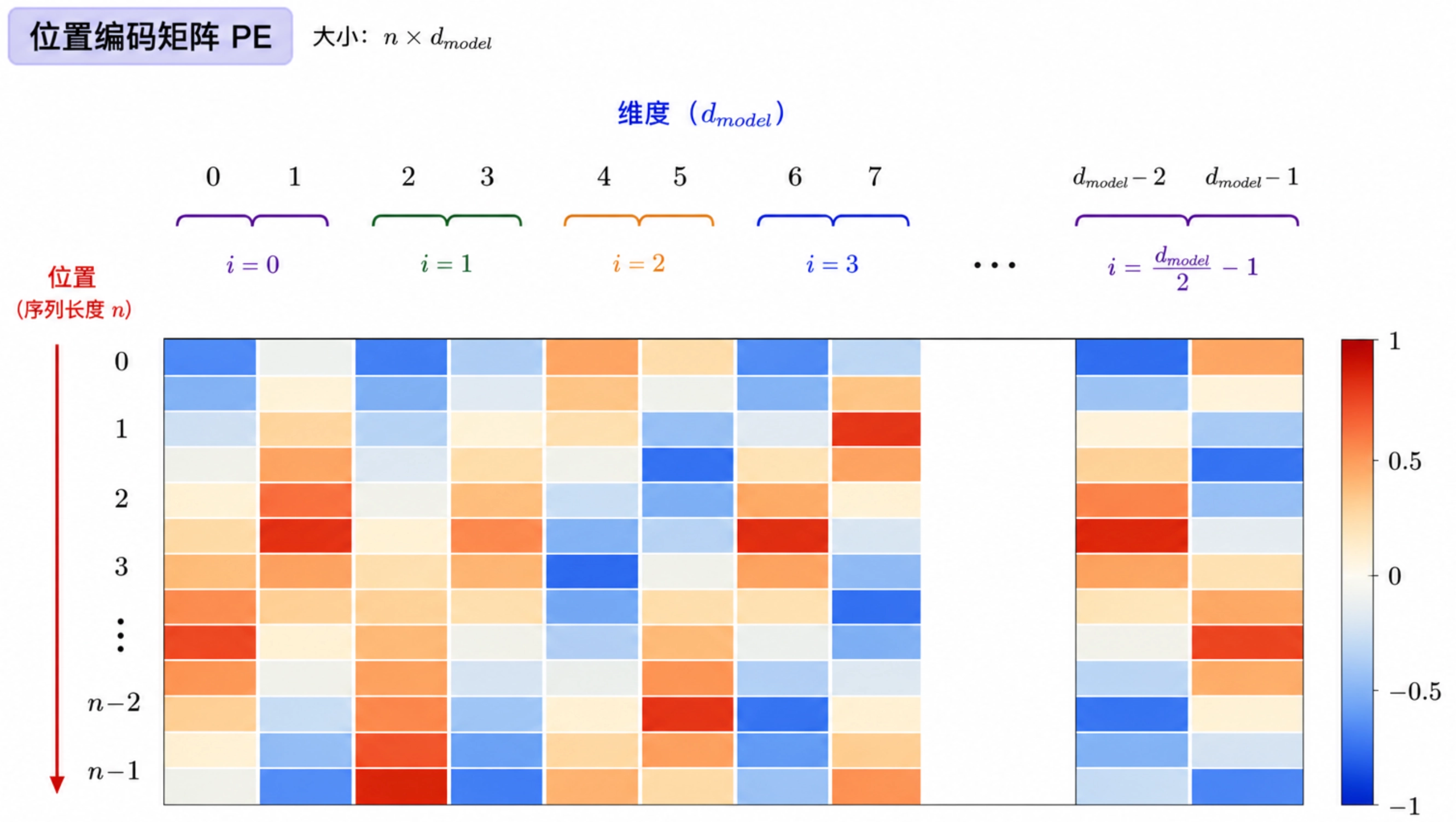
经典 Transformer 使用的是 固定正弦/余弦位置编码。具体来说,偶数维和奇数维使用不同函数:
这里:
- \(pos\) 表示 token 在序列中的位置索引
- \(i\) 表示维度索引对, \(2i\) 表示偶数维度索引,\(2i+1\) 表示奇数维度索引
为什么使用正弦/余弦
直接给每个位置一个编号也能区分先后,但编号是离散标量,表达能力比较弱。正弦/余弦位置编码会把位置展开成一个连续向量,并且让不同维度对应不同频率。
这样做有几个好处:
- 相邻位置的编码会平滑变化
- 不同距离的位置会呈现不同的向量模式
- 模型更容易通过线性变换学习相对位置关系
由于这套编码是固定公式生成的,它不依赖训练数据学习位置表;同一个位置在不同样本中会得到相同的位置编码。
Self-Attention
Self-Attention 是 Transformer 的核心机制。 它解决的问题是:序列中每个位置在更新自身表示时,应该参考序列中哪些其他位置,以及参考的程度有多大。
Self-Attention 的直观理解
Self-Attention 可以看作一种 sequence-to-sequence 的映射。 给定输入序列:\(a_1, a_2, ..., a_n\), 输出一个新的序列:\(b_1, b_2, ..., b_n\)。
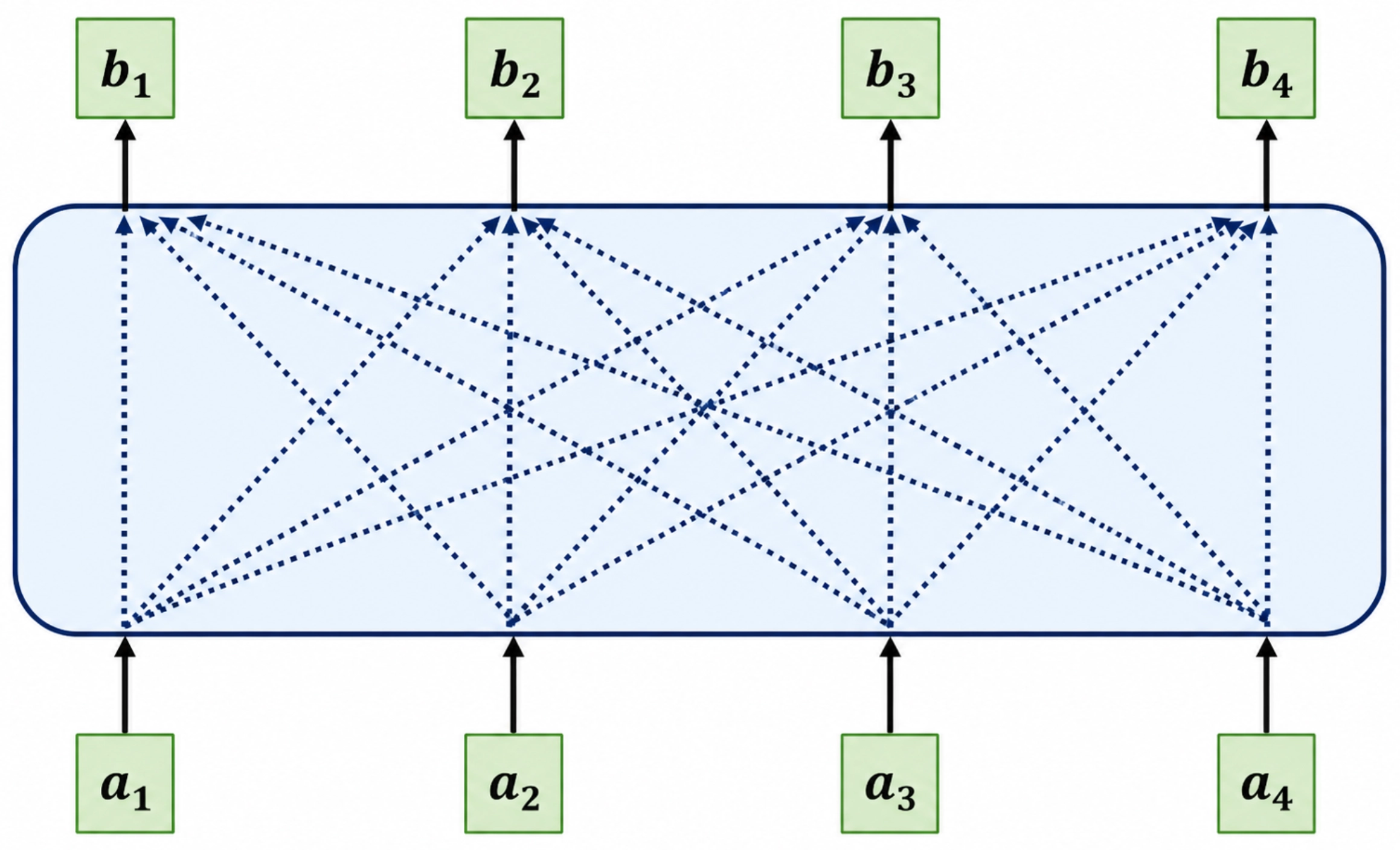
其中 \(a_i\) 可以是原始输入(embedding),也可以是某一层的 hidden states。 与传统模型不同的是,每个输出 \(b_i\) 都会关注整个输入序列, 即 \(b_i\) 是所有 \(a_j\) 的加权组合,从而融合了全局上下文信息。
相似度计算
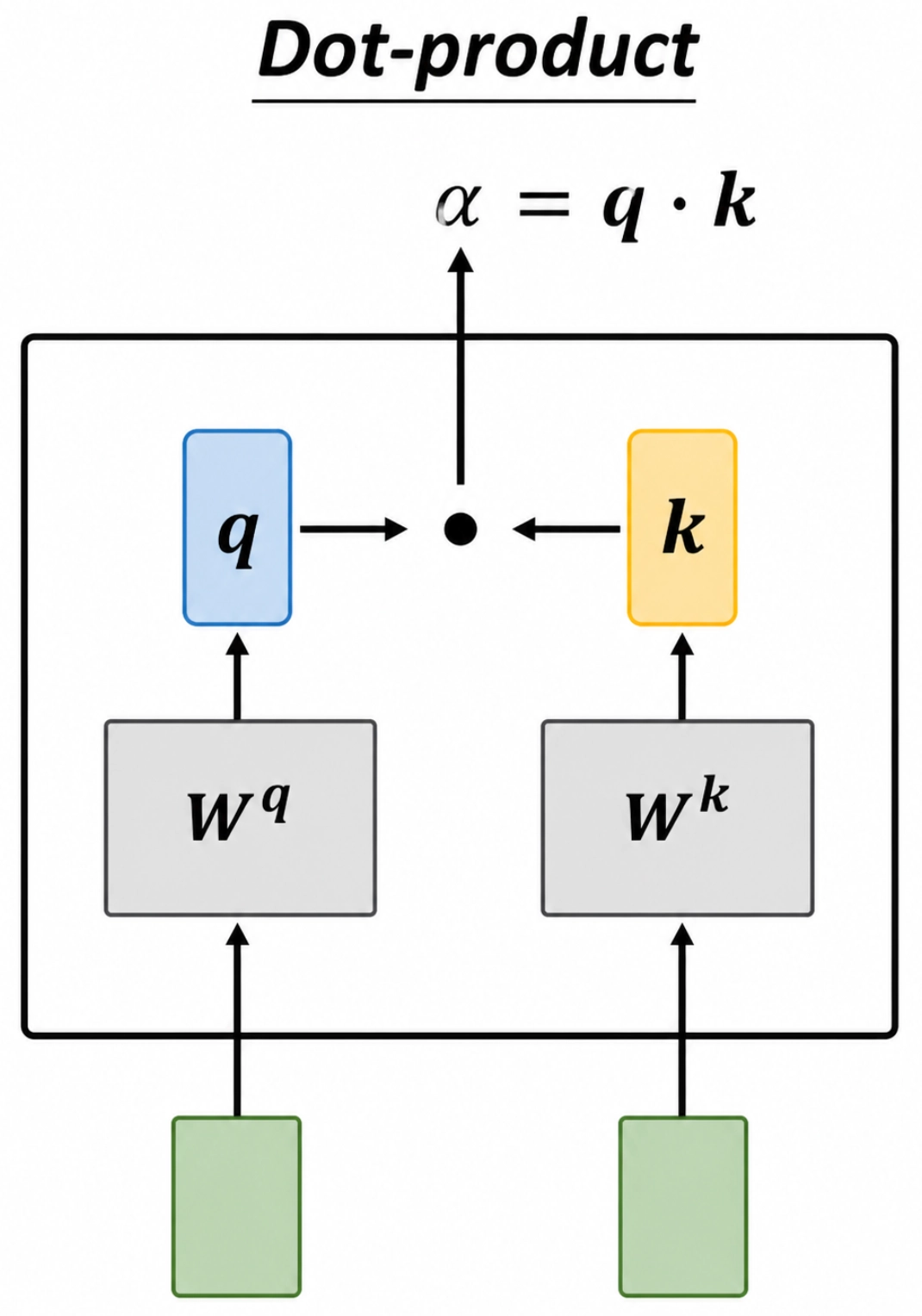
对于两个输入位置,模型不会直接拿原始向量做比较,而是先通过两组可学习参数分别得到:
- \(q\):通过将当前位置的输入表示映射到参数矩阵 \(W^Q\) 得到(即 Query 向量)
- \(k\):通过将被比较位置的输入表示映射到参数矩阵 \(W^K\) 得到(即 Key 向量)
然后用 \(q\) 和 \(k\) 做点积,得到一个标量分数:
相似度的计算方法有多种
Transformer 中采用的是计算高效的缩放点积注意力(Scaled Dot-Product Attention), 但在其他注意力机制中,也可以使用加性函数、余弦相似度等方式来计算相似度。
注意力权重计算
得到 query 和 key 之后,需要把“当前位置和其他位置有多相关”转换成一组可以用于加权求和的注意力权重。 这个过程通常包括以下几个步骤:
- 计算相似度分数 \(\alpha\)
- 缩放相似度分数,得到 \(\alpha / \sqrt{d_k}\)
- 对缩放后的分数做 softmax,得到注意力权重 \(\alpha'\)
计算第一个位置 \(a_1\) 对所有位置的注意力权重
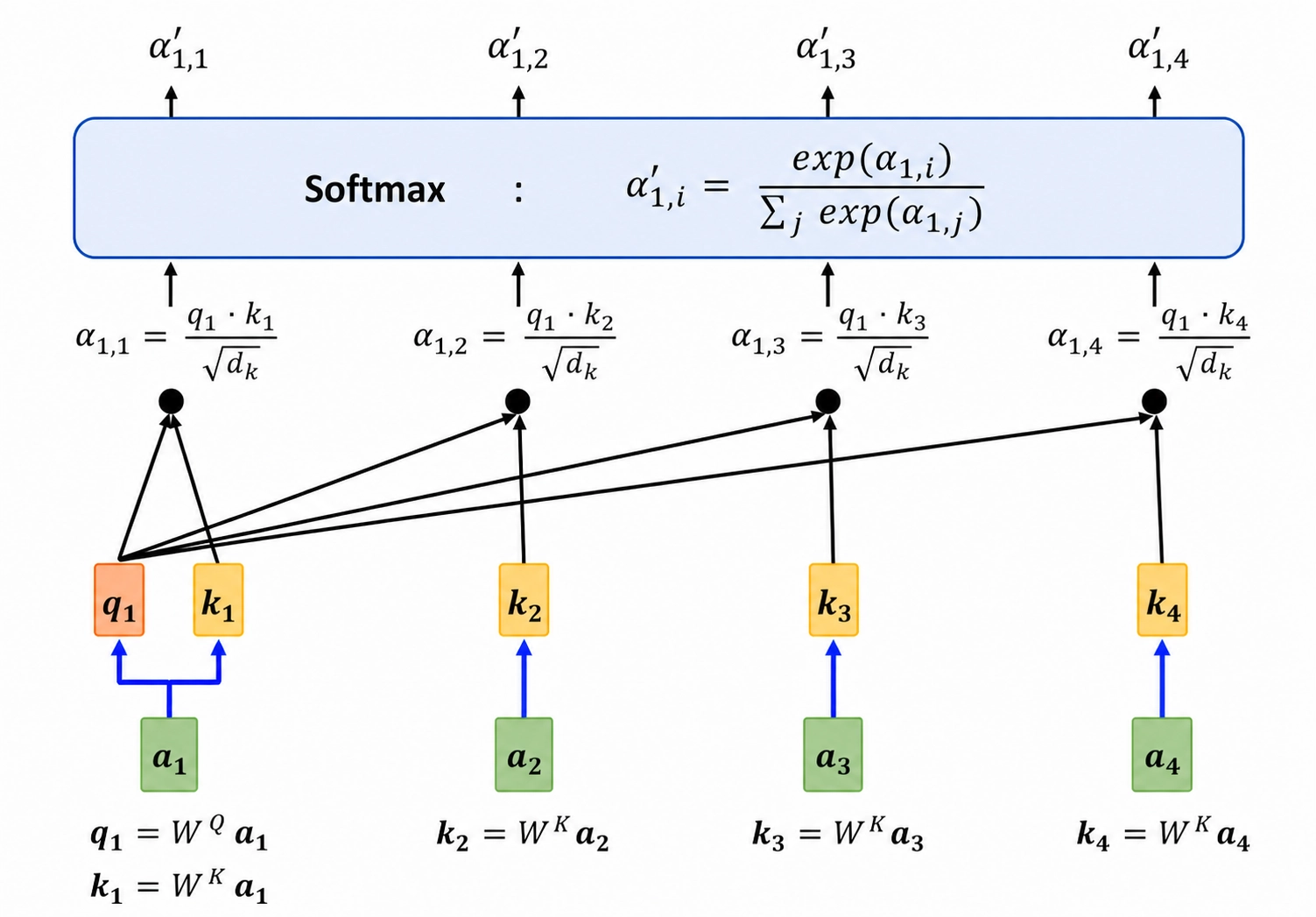
以上图为例,第 1 个位置的 \(q_1\) 会分别和 \(k_1, k_2, k_3, k_4\) 计算相似度:
经过缩放和 softmax 后,得到归一化后的注意力权重:
这样得到的一组权重 \([\alpha'_{1,1}, \alpha'_{1,2}, \dots, \alpha'_{1,n}]\) 会大于 0,且总和为 1。
为什么需要缩放
如果 \(d_k\) 很大,点积结果的数值范围通常会变大,softmax 容易进入非常陡的区域,导致:
- 某些位置权重过于接近 1
- 其余位置权重过于接近 0
- 梯度变小,训练不稳定
因此要用 \(\sqrt{d_k}\) 做缩放,让数值分布更平稳。
输出表示计算
得到注意力权重之后,就可以计算当前位置的输出表示。 每个位置的输出表示是所有位置的 value 向量的加权求和。
最终得到 self-attention 层的输出序列:
计算第一个位置 \(a_1\) 的输出表示 \(b_1\)
![]()
计算过程推导
矩阵表示习惯
下面的推导过程是参考李宏毅(Hung-yi Lee)教授的课程, 与经典 Transformer 论文中的向量/矩阵表示习惯略有不同,但在数学上是完全等价的。
主要区别在于:
- 将输入表示为行向量还是列向量
- 相应地,矩阵乘法的顺序(左乘或右乘)有所不同
这些差异仅属于表示方式的不同,不影响模型的实际计算结果与原理。
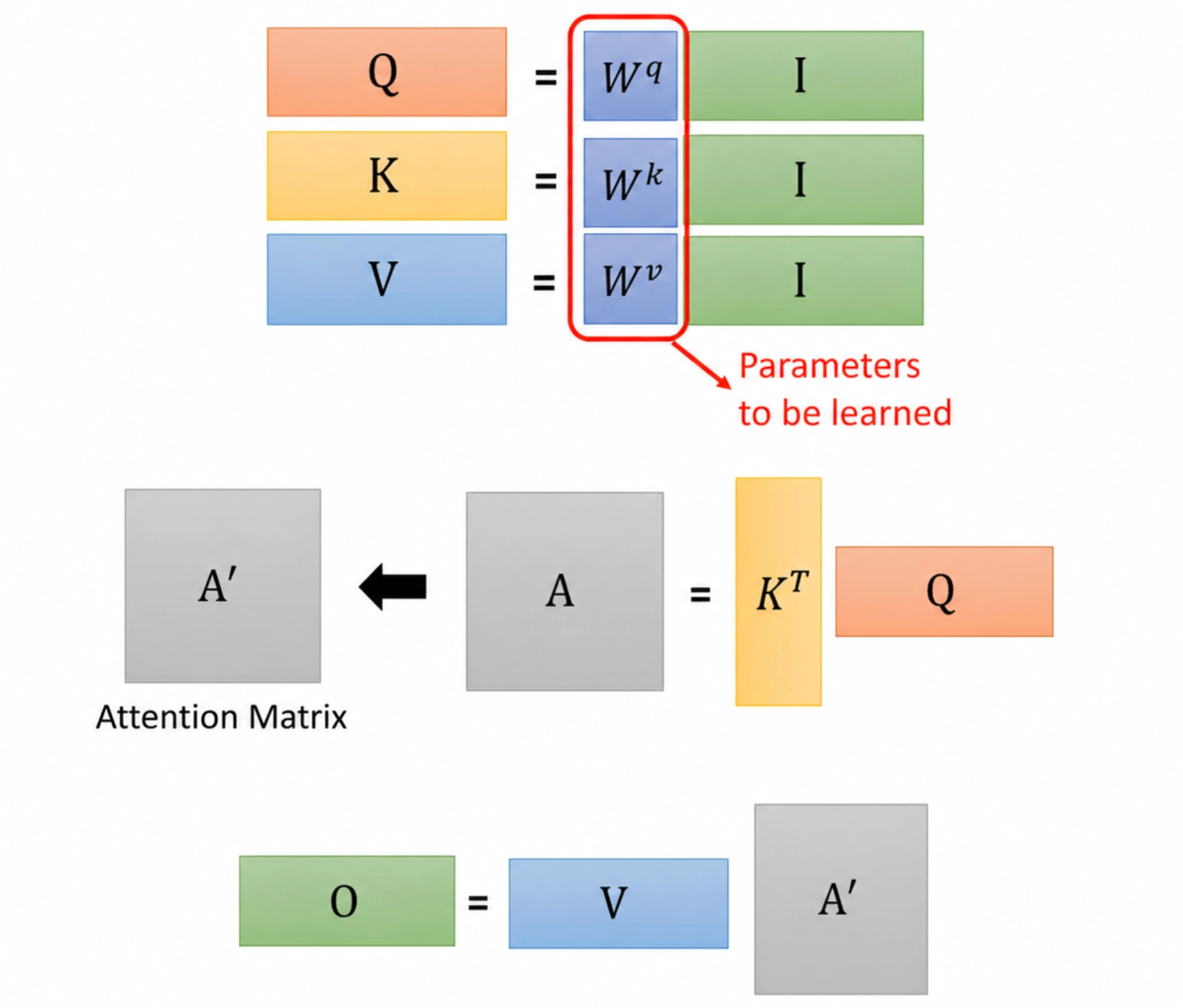
QKV 映射是 self-attention 的核心操作,用于将输入向量映射为 Query、Key、Value 向量,以便计算注意力权重并汇总信息。
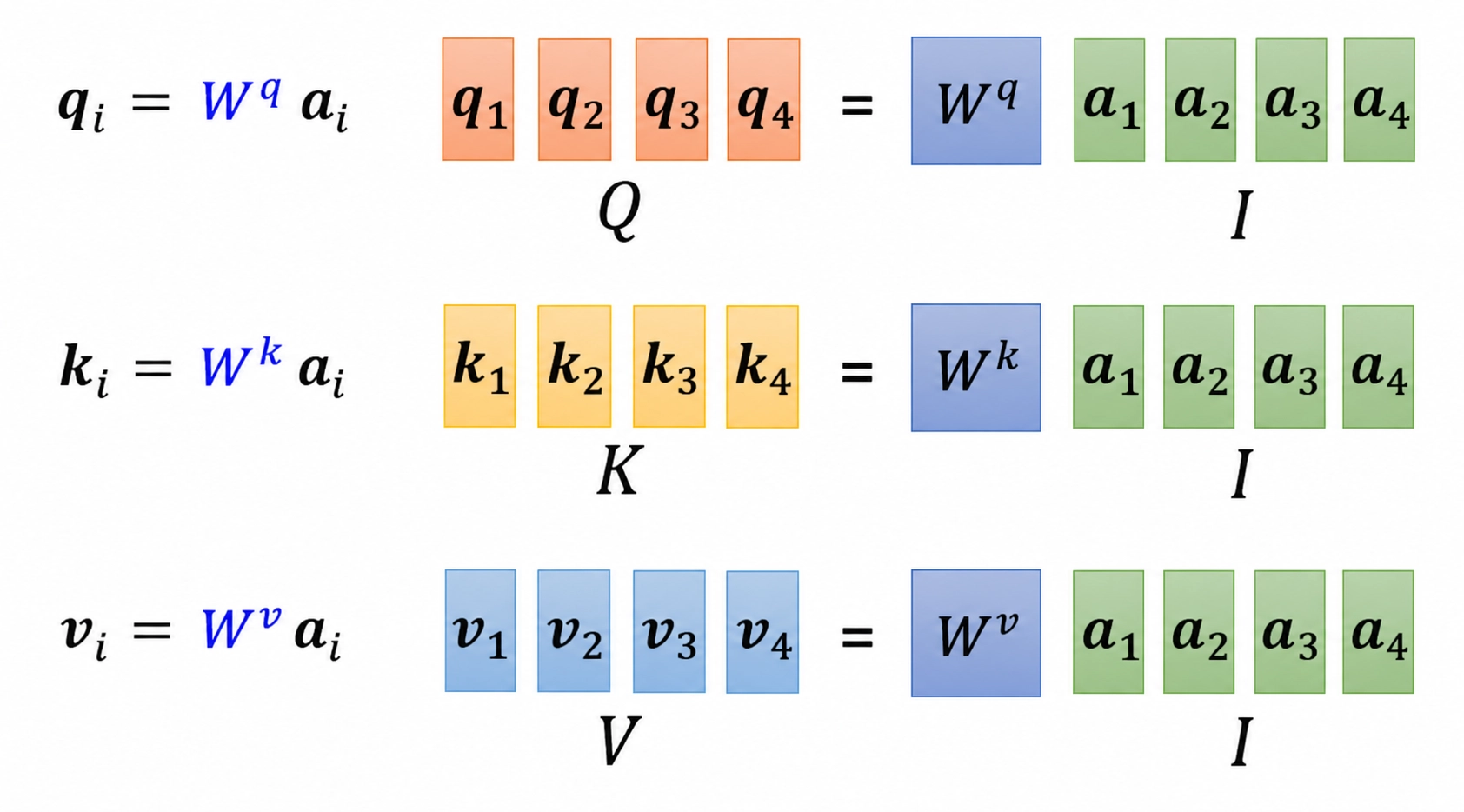
QKV 映射的理解
- Query:当前位置想要查询什么信息
- Key:每个位置能提供什么信息索引
- Value:每个位置真正携带的内容
注意力权重计算的矩阵表示为:

输出表示的矩阵表示为:
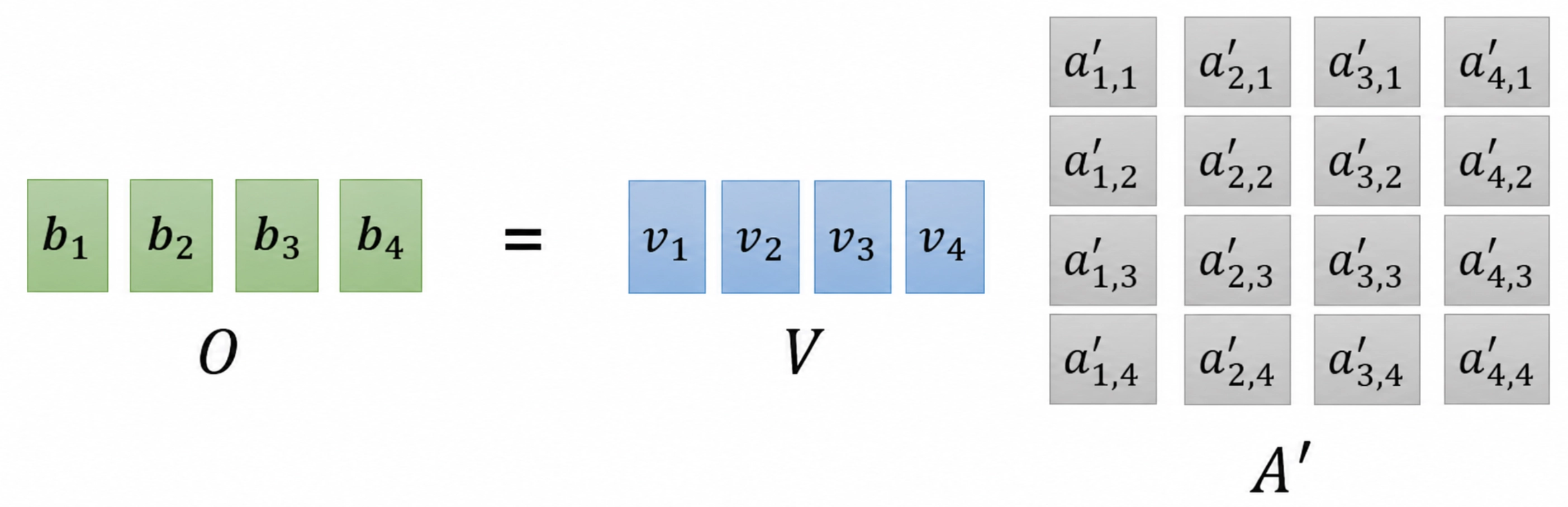
矩阵表示的抽象理解
上面几张图使用列向量表示,因此输出写成 \(O = VA'\)。如果改成经典 Transformer 论文和大多数代码实现中更常见的行向量表示,self-attention 的最终输出可以写成:
其中,在单个 self-attention head 的这一步里,\(W^Q, W^K, W^V\) 是训练得到的可学习参数;\(Q, K, V\)、注意力权重和输出表示都是中间计算结果。
张量流转
如果输入长度是 \(n\),模型维度是 \(d_{model}\),那么 self-attention 的核心张量变化可以概括为:
- 输入:\(X \in \mathbb{R}^{n \times d_{model}}\)
- 投影后:\(Q, K \in \mathbb{R}^{n \times d_k}\),\(V \in \mathbb{R}^{n \times d_v}\)
- 分数矩阵:\(QK^T \in \mathbb{R}^{n \times n}\)
- 权重矩阵:\(A' \in \mathbb{R}^{n \times n}\)
- 输出:\(A'V \in \mathbb{R}^{n \times d_v}\)
也就是说,attention 先算“谁关注谁”,再按这个权重对 value 做加权求和。
Multi-Head Attention
每个 attention head 都会通过独立的线性投影,将输入映射到一个表示子空间中进行注意力计算。Transformer 的做法是:并行使用多个 attention head,让不同 head 在不同子空间里学习不同类型的依赖关系。
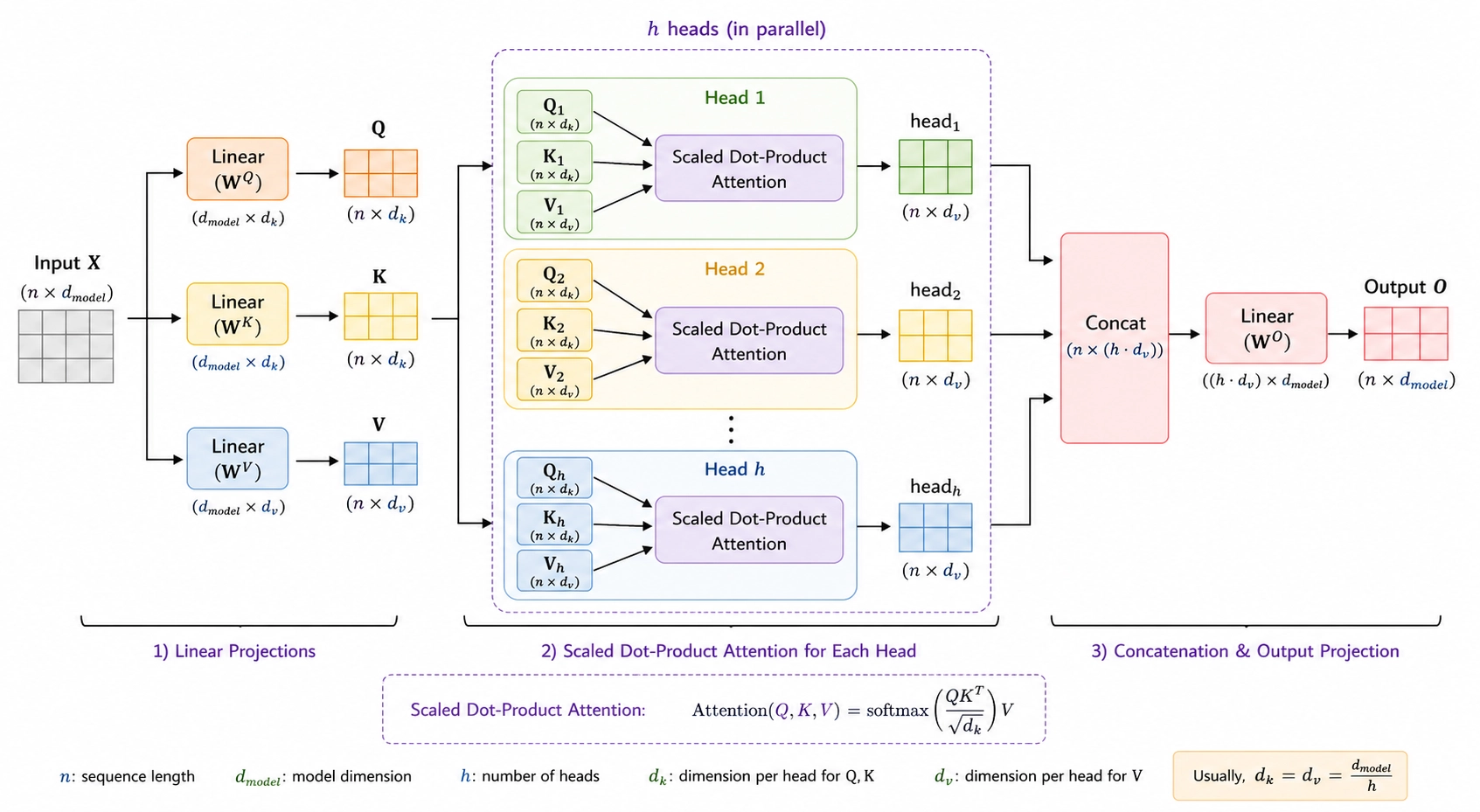
Multi-Head Attention 的定义可以写成:
其中第 \(i\) 个 head 为:
这里的 \(Q,K,V\) 表示传给 attention 层的三组输入表示,而不是已经投影完成的 query/key/value。\(W_i^Q,W_i^K,W_i^V\) 才是第 \(i\) 个 head 自己的投影矩阵。也就是说,每个 head 会把输入表示投影到自己的子空间中,独立计算一次 scaled dot-product attention。
QKV 的来源
在 encoder self-attention 中,三组输入表示都来自同一个输入 \(X\)。如果暂时不考虑各个 head 内部的投影矩阵,可以直观理解为:
更严格地说,每个 head 仍然会使用不同的投影矩阵得到自己的 \(Q_i,K_i,V_i\):
多个 head 的输出会在特征维度上拼接起来,最后再经过输出投影矩阵 \(W^O\),得到最终输出。这里使用 concat 而不是直接相加,是为了保留不同 head 各自学到的信息,再交给 \(W^O\) 做统一混合。
其中参数维度通常为:
- \(W_i^Q \in \mathbb{R}^{d_{model} \times d_k}\)
- \(W_i^K \in \mathbb{R}^{d_{model} \times d_k}\)
- \(W_i^V \in \mathbb{R}^{d_{model} \times d_v}\)
- \(W^O \in \mathbb{R}^{h d_v \times d_{model}}\)
经典 Transformer 论文的 base 设置中使用 \(h = 8\) 个 head,\(d_{model}=512\),因此:
由于每个 head 的维度被降到 \(d_{model}/h\),multi-head attention 虽然并行计算了多个 head,但总体计算复杂度仍然和一个完整维度的 single-head attention 处于同一量级。
为什么需要 Multi-Head Attention
不同的 head 往往会关注不同模式,例如:
- 句法依赖
- 长距离指代关系
- 局部邻近关系
- 特定位置的语义对齐关系
这使得模型不必把所有关系都压进一个注意力分布里,而是能在多个子空间里并行建模。 Multi-head attention 不是把多个独立模型做 ensemble,而是把同一个表示拆到多个投影子空间中分别建模,再把结果合并。 可以把它理解成:不是让一个人同时完成所有观察任务,而是让多个观察者从不同角度看同一段序列,最后再把结果汇总。
Feed Forward Network
在 attention 之后,Transformer 会对每个位置单独应用一个前馈网络(Feed Forward Network, FFN)。它也常被称为 Position-wise Feed-Forward Network,意思是:每个位置都会经过同一个前馈网络,但不同位置之间不会在 FFN 内部直接交互。
经典形式通常写成:
其中 \(\max(0, \cdot)\) 表示 ReLU 激活函数。对于单个位置的输入向量 \(x \in \mathbb{R}^{d_{model}}\),通常有:
- \(W_1 \in \mathbb{R}^{d_{model} \times d_{ff}}\)
- \(b_1 \in \mathbb{R}^{d_{ff}}\)
- \(W_2 \in \mathbb{R}^{d_{ff} \times d_{model}}\)
- \(b_2 \in \mathbb{R}^{d_{model}}\)
它有两个特点:
- 对每个位置独立计算
- 参数在所有位置共享
也就是说,attention 负责“位置之间交换信息”,而 FFN 负责“对每个位置的表示再做一次非线性变换”。可以把它理解成:attention 先为每个位置汇总上下文,FFN 再对每个位置的特征维度进行加工。
张量维度理解
如果输入维度是 \(d_{model}\),中间隐藏层维度是 \(d_{ff}\),那么:
- 输入:\(n \times d_{model}\)
- 第一层线性变换后:\(n \times d_{ff}\)
- 第二层线性变换后:\(n \times d_{model}\)
这样 FFN 处理完之后,维度又回到原来的模型维度,方便继续堆叠下一层 block。
经典 Transformer base 设置中:
也就是先把每个位置的表示从 512 维升到 2048 维,再降回 512 维。
Add & Norm
Transformer 的每个子层外面都会包一层 残差连接(Residual Connection) 和 层归一化(Layer Normalization)。在结构图中,这一部分通常标成 Add & Norm:
- Add:把子层输出和原始输入相加,也就是残差连接
- Norm:对相加后的结果做 LayerNorm
可以抽象写成:
其中:
Sublayer(x)可以是 Multi-Head Attention- 也可以是 Feed Forward Network
这里 \(x\) 和 \(\text{Sublayer}(x)\) 的维度必须相同,才能直接相加。这也是为什么 Multi-Head Attention 和 FFN 的输出都会回到 \(d_{model}\) 维。
为什么需要残差连接
残差连接的作用主要有两个:
- 保留原始输入信息,避免每层都完全重写表示
- 让深层网络训练更稳定,梯度更容易传播
为什么需要 LayerNorm
LayerNorm 会对每个位置的特征维度做归一化,帮助:
- 稳定数值分布
- 加快收敛
- 降低训练波动
这套 Add & Norm 结构是 Transformer 能够稳定堆叠多层的重要原因之一。
Post-Norm 与 Pre-Norm
原始 Transformer 论文中的写法是:
也就是先做残差相加,再做 LayerNorm,通常称为 Post-Norm。
后续很多更深的 Transformer 变体会采用 Pre-Norm:
Pre-Norm 通常更利于深层模型训练稳定,但本文讲解经典 Transformer 时仍以原论文的 Post-Norm 形式为主。
Encoder
Encoder 由多个完全同构的 Encoder Block 堆叠而成。
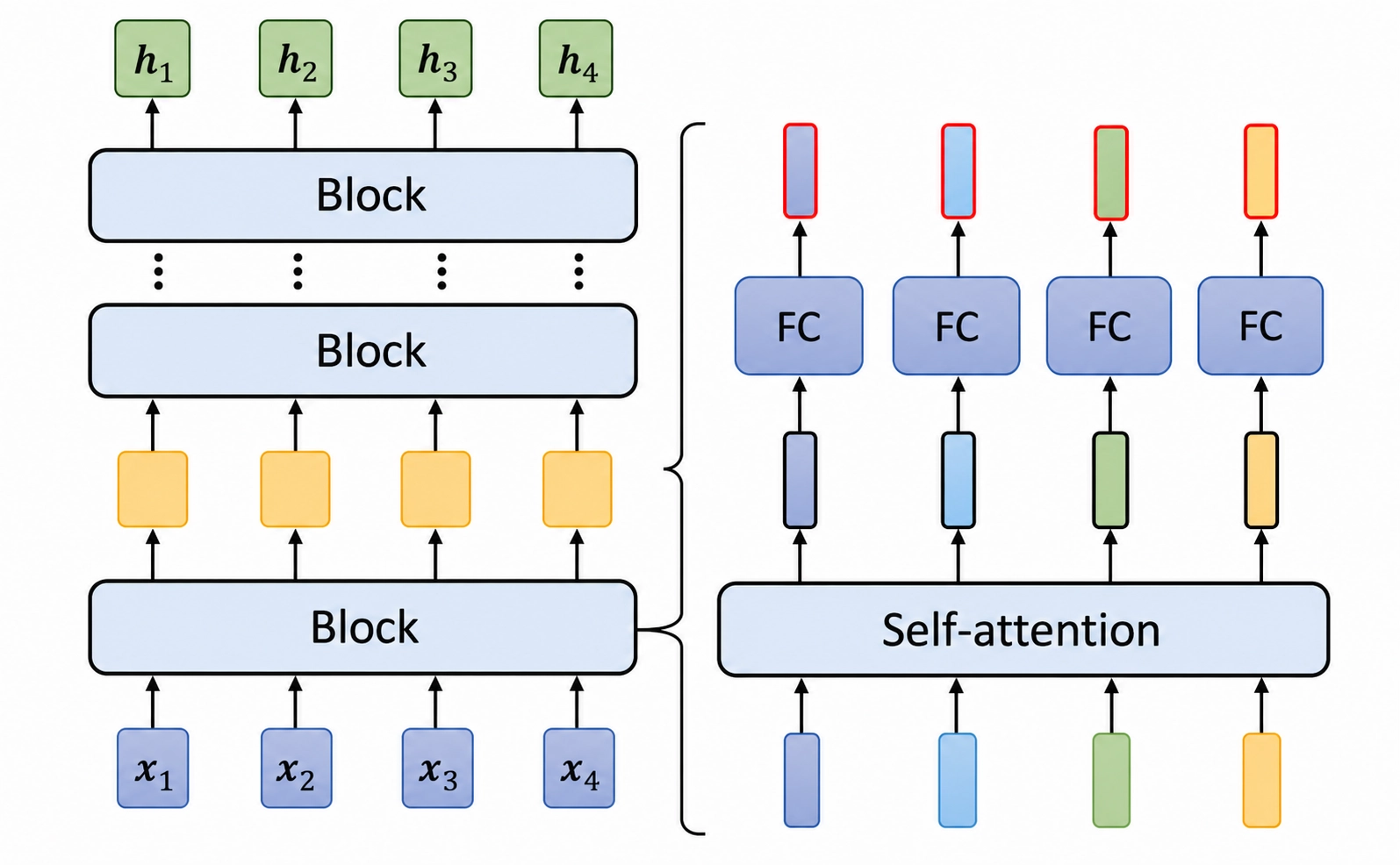
每个 Encoder Block 包含:
- Multi-Head Self-Attention
- Add & Norm
- Feed Forward Network
- Add & Norm
Encoder 的输入是带有位置信息的 token 表示,输出则是每个位置的上下文化表示。
Encoder 的工作重点
在 encoder 中,每个 token 都可以看见整句输入中的其他 token,因此得到的表示不再只是词本身,而是:
- 当前词的语义
- 它与上下文的关系
- 它在整个句子中的角色
例如在翻译任务里,encoder 输出的不只是某个词的 embedding,而是“结合整句上下文之后”的表示。
Decoder
Decoder 也是由多个同构 block 堆叠而成,但比 encoder 多一个 attention 子层。
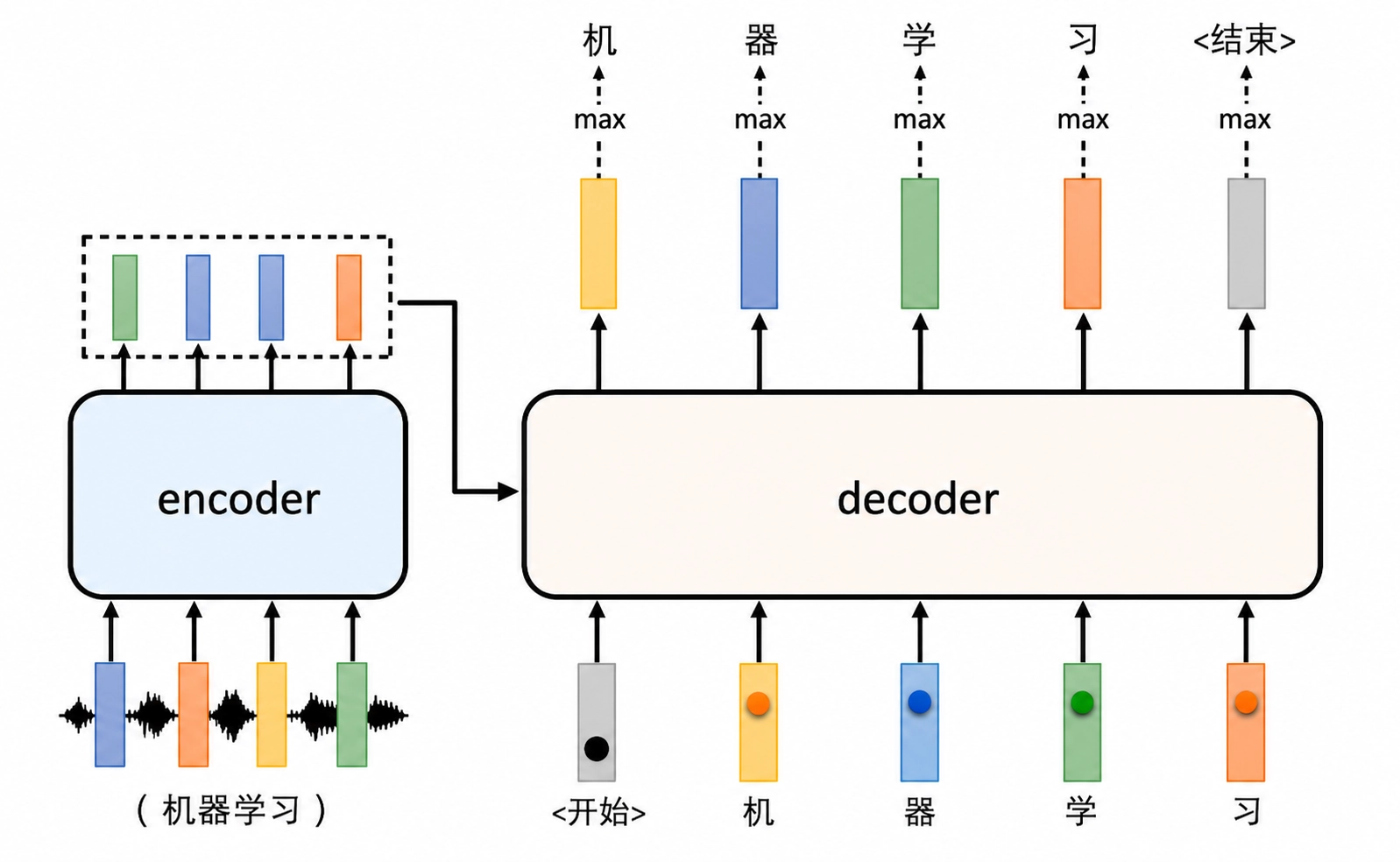
每个 Decoder Block 包含:
- Masked Multi-Head Self-Attention
- Add & Norm
- Encoder-Decoder Attention
- Add & Norm
- Feed Forward Network
- Add & Norm
Decoder 的理解
可以把 decoder 理解成一个“边看输入、边参考已经生成内容、边决定下一个 token”的过程。
Masked Self-Attention
Decoder 在生成第 \(t\) 个位置时,只能看到自己以及前面的 token,不能偷看后面的正确答案。 因此这里会使用 causal mask。
Encoder-Decoder Attention
这一步里:
- Query 来自 decoder 当前表示
- Key 和 Value 来自 encoder 输出
公式形式和普通 attention 一样,只是来源不同:
它的作用是让 decoder 在生成当前 token 时,能够有针对性地读取输入序列中的相关信息。
Mask 机制
Mask 是经典 Transformer 里非常关键的一部分,主要用于控制“哪些位置允许被关注”。
Padding Mask
在一个 batch 中,不同样本的长度往往不同,短序列通常会补 padding token。
这些 padding 位置并不是真实内容,因此 attention 不应该把权重分给它们。
Padding mask 的作用就是:
- 屏蔽无效补齐位置
- 避免无意义的 token 干扰表示学习
Causal Mask
Decoder 自回归生成时,位置 \(t\) 不能看到未来位置 \(t+1, t+2, ...\)。
因此会使用一个上三角屏蔽矩阵。例如长度为 4 时,可以理解成:
[0, -inf, -inf, -inf]
[0, 0, -inf, -inf]
[0, 0, 0, -inf]
[0, 0, 0, 0]
加到 attention 分数上后,再做 softmax,被屏蔽位置的权重就会接近 0。
为什么 mask 很重要
如果没有 mask:
- padding 会污染 attention 分布
- decoder 训练时会看到未来答案,导致训练和推理不一致
所以 mask 本质上是在把模型的“可见范围”限制成任务允许的范围。
整体流程
经典 Transformer 在训练和推理阶段的行为并不完全相同。
训练阶段
训练时通常使用 teacher forcing:
- decoder 的输入是目标序列右移后的版本
- 每个位置都预测下一个 token
- 因为有 causal mask,所以虽然可以并行计算整段输出,但每个位置仍然只能依赖过去内容
这使得 Transformer 在训练时能够高效并行。
推理阶段
推理时没有真实目标序列可用,因此只能:
- 先输入起始 token
- 预测下一个 token
- 把预测结果接回 decoder 输入
- 再继续预测下一个 token
也就是说,训练时可并行,生成时通常仍是自回归逐步生成。
训练与推理的差异
- 训练:一次性处理整句目标序列,但每个位置受 causal mask 约束
- 推理:每次只新增一个 token,再继续下一步
优点与局限
-
Transformer 的优点
- 更容易建模长距离依赖
- 训练时并行性好
- 模块化清晰,易于扩展
- 在 NLP 任务上表现非常强,后来也扩展到视觉、多模态等方向
-
Transformer 的局限
- Self-Attention 的计算和显存开销会随序列长度增长较快
- 经典位置编码对超长序列的泛化有限
- 推理阶段仍然可能是逐步生成,速度未必总是理想
- 对数据规模和算力通常有较高要求
适用场景
经典 Transformer 最典型的使用场景是 序列到序列任务,尤其适合:
- 机器翻译
- 文本摘要
- 问答与阅读理解
- 语音识别中的序列建模部分
- 需要建模长距离依赖的 NLP 任务
从历史上看,Transformer 最先在 NLP 中大获成功,后续很多模型虽然做了各种变体和增强,但核心思想依然建立在 attention 和 encoder/decoder 或 decoder-only 结构之上。