CNN
卷积神经网络(Convolutional Neural Network, CNN)是一类特别适合处理图像、视频、语音频谱等网格结构数据的神经网络。
CNN 的核心思想
- 利用局部连接捕捉邻域特征
- 利用权重共享减少参数量
- 通过多层堆叠,从低级特征逐步抽取到高级语义特征
核心组件
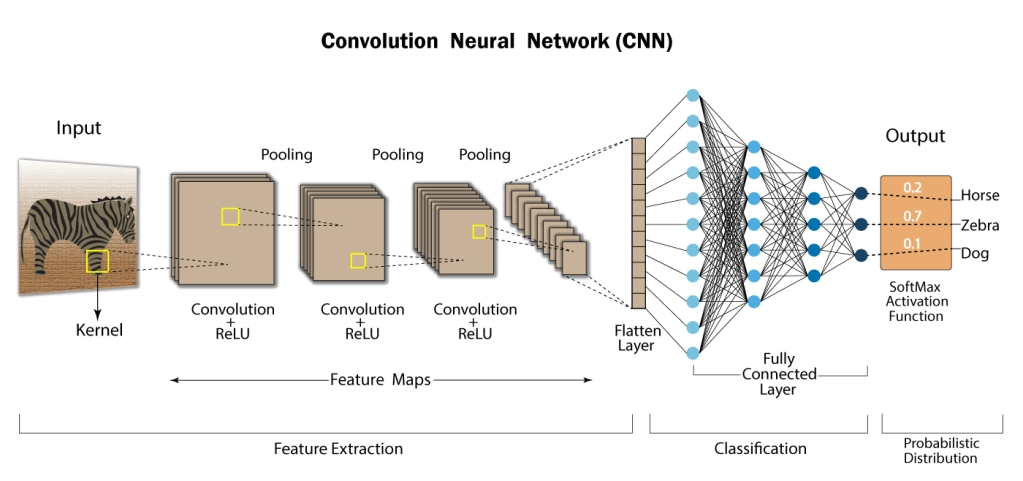
CNN 通常由以下几类层组成:
- 卷积层(Convolution Layer)
- 激活函数(通常是 ReLU)
- 池化层(Pooling Layer)
- 全连接层(Fully Connected Layer)
- 输出层(如 Softmax)
卷积层
卷积层是 CNN 最核心的部分。
它会使用若干个小的卷积核(Kernel / Filter)在输入上滑动,对局部区域做加权计算,生成新的特征图(Feature Map)。
卷积核的直观理解
可以把卷积核理解成一个“特征探测器”:
- 有的卷积核擅长检测边缘
- 有的卷积核擅长检测纹理
- 有的卷积核擅长检测颜色变化
随着网络变深,后面的卷积层会在前面特征的基础上进一步组合,学到更复杂的结构:
- 浅层:边缘、角点、简单纹理
- 中层:局部形状、重复模式
- 深层:眼睛、轮子、耳朵、物体轮廓等语义结构
参数共享
CNN 很重要的一点是权重共享。同一个卷积核会在整张图上重复使用,这意味着:
- 检测“横向边缘”的参数不需要为每个像素位置单独学习
- 参数量远小于全连接层
- 模型更容易泛化
输出尺寸
卷积层输出尺寸通常由以下几个参数决定:
kernel size:卷积核大小stride:步幅padding:边缘填充out channels:卷积核个数
二维卷积的输出高宽常见计算公式为:
输出尺寸计算
例如输入是 32 x 32,卷积核是 3 x 3,步幅是 1,padding 是 1,那么输出仍然是 32 x 32。
激活函数
卷积之后通常会接一个非线性激活函数,否则多层线性变换叠起来仍然只是线性模型。
CNN 最常见的是 ReLU:
它的优点是:
- 计算简单
- 收敛快
- 在深层网络中比 Sigmoid / Tanh 更实用
池化层
池化层(Pooling Layer)用于对特征图做下采样,最常见的是 Max Pooling。

Max Pooling 的作用
- 降低计算量
- 压缩特征图尺寸
- 增强一定程度的位置不敏感性
- 减少过拟合风险
不是所有现代 CNN 都依赖池化
在一些较新的架构里,也会直接使用 stride convolution 代替 pooling。
特征图
卷积层输出的结果通常叫做 特征图(Feature Map)。 如果一层有多个卷积核,就会产生多个特征图:
- 一个卷积核对应一张特征图
- 多个卷积核提取不同类型的模式

因此,CNN 中的通道数(channels)常常会随着网络变深而增加,表现为:
- 空间分辨率下降
- 特征维度上升
感受野
感受野(Receptive Field)指的是:某一层中的一个神经元,能“看到”原始输入中的多大区域。

感受野决定了模型能够获取的上下文范围。随着卷积层数的增加,神经元的感受野会逐渐变大,从只能感知局部,到能够利用更大范围的结构信息。
如果堆叠 3 个 3 x 3 的卷积层,并且保持滑动窗口步长为1,其感受野就是 7 x 7 的了。既然感受野和一个 7 x 7 卷积核一样大,那为什么很多网络更喜欢堆叠多个小卷积呢?
对于输入尺寸为 \(h \times w \times c\),若每层都使用 \(c\) 个卷积核(得到 \(c\) 个特征图),我们来对比下不同设置下的参数量:
- 使用一个 \(7 \times 7\) 卷积核:需要的参数量为 \(c \times (7 \times 7 \times c) = 49c^2\)
- 堆叠三个 \(3 \times 3\) 卷积核:总参数量为 \(3 \times c \times (3 \times 3 \times c) = 27c^2\)
可以看出,采用多个小卷积核堆叠,不仅参数更少,还能引入更多的非线性变换(每次卷积后可接激活函数),使网络具备更强的特征提取能力。
也就是说,它们的感受野可以一样大,但计算过程和表达能力并不一样。多个小卷积并不是在“复现同一个 7 x 7 卷积”,而是在用更少参数构造一个更深、更有非线性的特征提取过程。
✅ 这正是 VGG 网络的设计思想:用多个 \(3 \times 3\) 小卷积核堆叠,既减少参数,又提升表达力。
层级特征
CNN 的强大之处在于它能自动学习层级化表示。
大致可以理解为:
| 层级 | 学到的内容 |
|---|---|
| 浅层 | 边缘、方向、亮暗变化 |
| 中层 | 纹理、局部部件、重复模式 |
| 深层 | 物体局部、类别相关语义特征 |
这也是为什么 CNN 在图像分类、目标检测、分割等任务中长期非常有效。
常见经典模型
- LeNet:早期手写数字识别模型
- AlexNet:推动深度学习在计算机视觉中爆发
- VGG:堆叠大量
3 x 3卷积 - ResNet:引入残差连接,解决深层网络训练困难
这些模型虽然结构不同,但核心思想都建立在卷积特征提取之上。
优点与局限
-
CNN 的优点
- 对图像空间结构建模更自然
- 参数量显著少于纯全连接网络
- 适合自动提取局部模式
- 在视觉任务中效果稳定、成熟
-
CNN 的局限
- 对全局依赖建模不如 Transformer 直接
- 对输入分辨率、位移和尺度变化并不是完全鲁棒
- 深层 CNN 训练仍然需要较多数据和算力
- 设计卷积层数、通道数、下采样方式时有不少工程权衡
训练关注点
训练 CNN 时,一般会重点看这些点:
- 输入归一化是否合理
- 数据增强是否充分
- 模型是否过拟合
- 卷积层数量和通道数是否匹配任务规模
- 学习率、batch size、优化器是否稳定
图像任务里常用的数据增强
常见操作如下,通常可以显著提升泛化能力:
- 随机裁剪
- 翻转
- 颜色扰动
- 随机旋转
适用场景
CNN 依然非常适合这些任务:
- 图像分类
- 目标检测中的 backbone
- 图像分割
- OCR
- 医学影像分析
- 语音频谱建模
如果任务强依赖局部模式、并且输入是规则网格结构,CNN 往往仍然是非常靠谱的基线。
为什么图像任务适合 CNN
相比普通全连接网络,CNN 更擅长处理空间结构明显的数据,比如图像中的边缘、纹理、形状和目标区域。
CNN 与全连接网络的区别
| 对比项 | 全连接网络 | CNN |
|---|---|---|
| 输入处理 | 通常展平 | 保留二维/三维结构 |
| 参数规模 | 大 | 相对更小 |
| 是否利用空间局部性 | 否 | 是 |
| 图像任务适配度 | 一般 | 很强 |
全连接网络的参数量
假设输入是一张 224 x 224 x 3 的图片。
如果直接把它展开后送入全连接层,输入维度就是:
如果下一层有 1000 个神经元,那么单层参数量就是:
这会带来几个问题:
- 参数太多,训练成本高
- 很容易过拟合
- 图像的空间结构被破坏了
而 CNN 的卷积核只关注局部区域,比如 3 x 3 或 5 x 5,并且同一个卷积核会在整张图上滑动复用,所以既保留了空间结构,也显著减少了参数量。