RNN
循环神经网络(Recurrent Neural Network, RNN)是一类专门用于处理序列数据(Sequential Data)的神经网络。
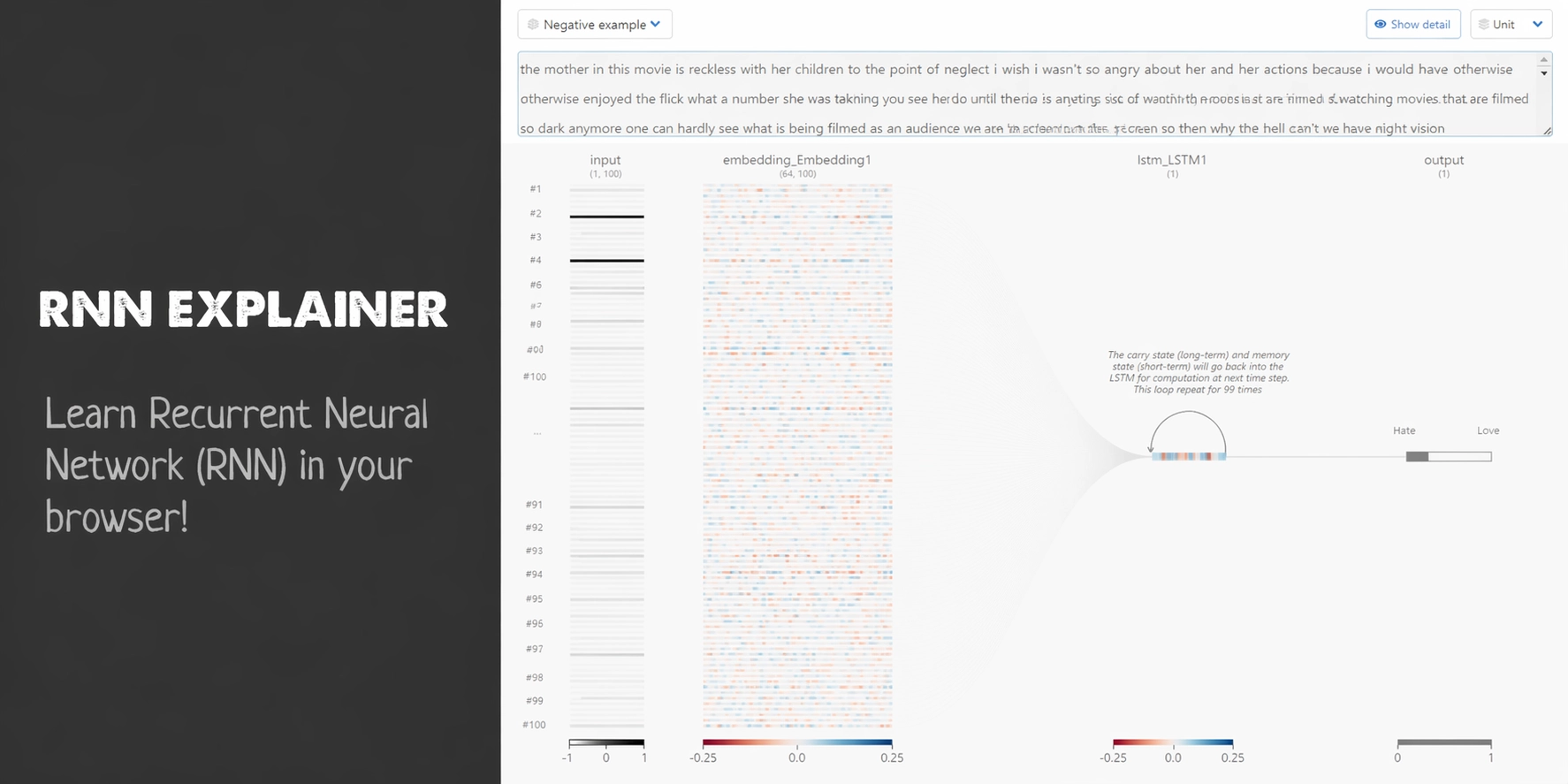
RNN 的核心思想
- 输入不是孤立样本,而是按时间顺序展开的序列
- 当前时刻的输出不仅依赖当前输入,也依赖历史信息
- 同一组参数会在不同时间步重复使用
背景
很多任务天然带有顺序关系,样本之间不是独立的:
- 文本中的词有上下文关系
- 语音信号具有时间连续性
- 时间序列数据依赖历史观测值
- 用户行为序列往往与前面的动作相关
如果使用普通全连接网络,通常需要把整个序列一次性展开输入,这样会:
- 丢失顺序结构的表达优势
- 参数量变大
- 难以自然处理变长序列
RNN 的设计正是为了解决这类问题。
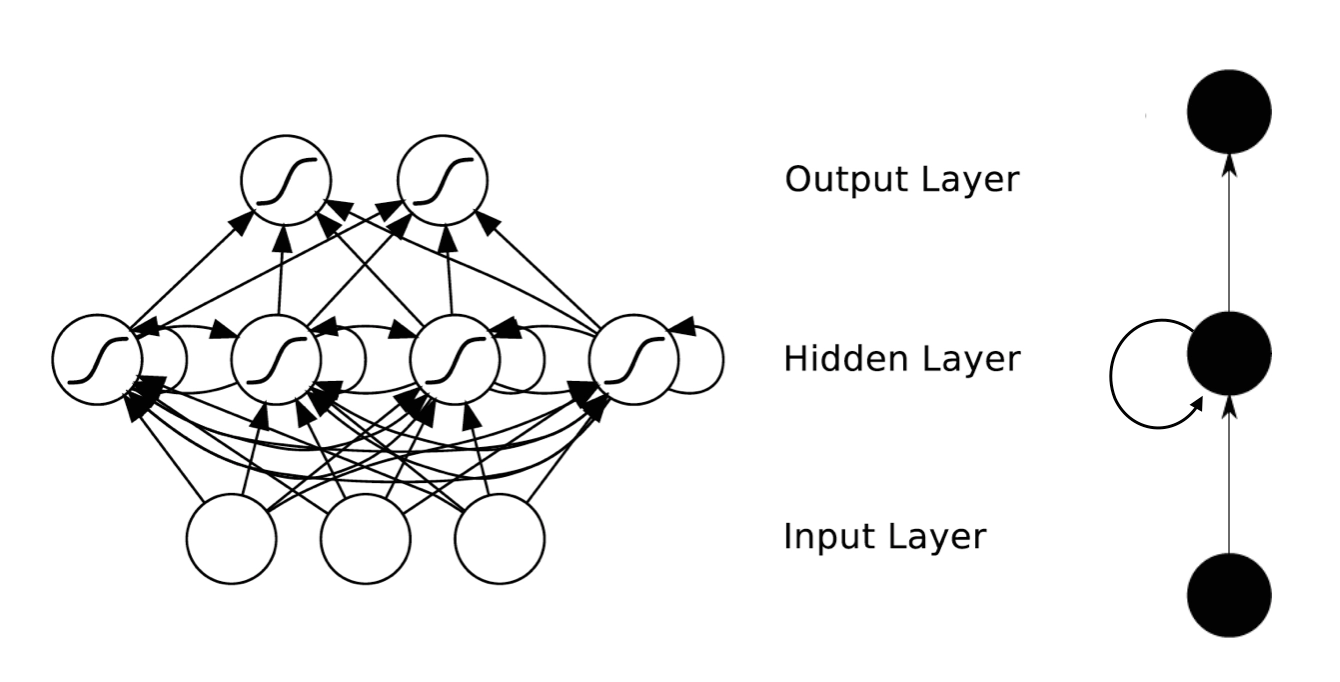
基本结构
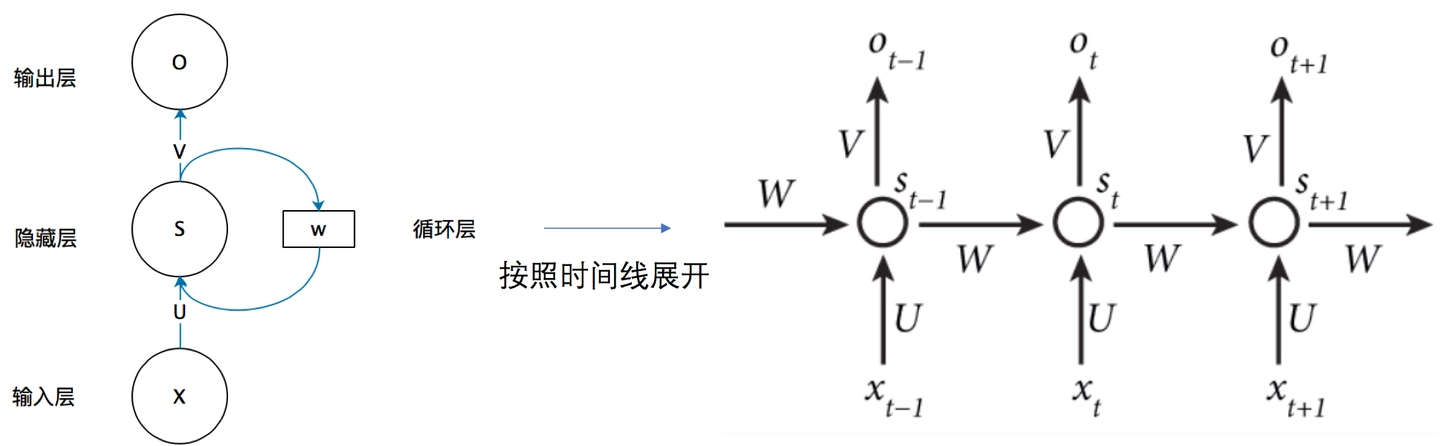
RNN 的基本结构如下:
RNN 在每一个时间步都会接收:
- 当前输入 \(x_t\)
- 上一个时间步的隐藏状态 \(h_{t-1}\)
然后计算新的隐藏状态:
再基于隐藏状态产生输出:
其中:
- \(x_t\) 表示第 \(t\) 个时间步的输入
- \(h_t\) 表示第 \(t\) 个时间步的隐藏状态
- \(y_t\) 表示第 \(t\) 个时间步的输出
- \(U\) 表示输入到隐藏状态的权重
- \(W\) 表示上一时刻隐藏状态到当前隐藏状态的权重
- \(V\) 表示隐藏状态到输出的权重
- \(f\) 表示非线性激活函数,比如
tanh
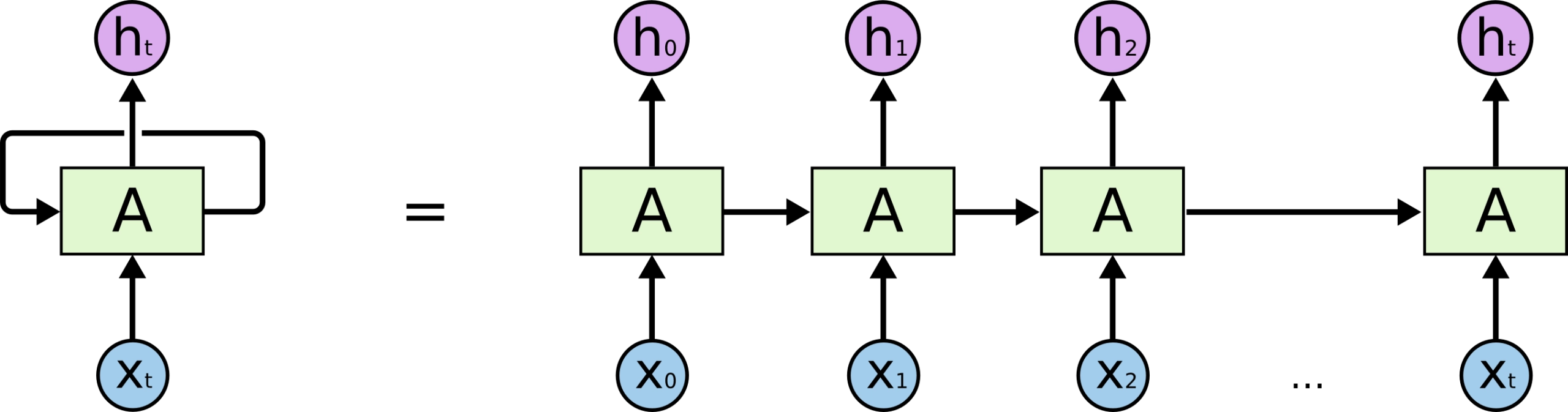
时间展开
RNN 通常会在概念上沿时间轴展开来看。
虽然看起来像很多层串联起来,但这些时间步共享同一组参数:
- 第 1 个时间步使用参数 \(W, U, V\)
- 第 2 个时间步仍然使用参数 \(W, U, V\)
- 后续所有时间步都复用同一组参数
这就是 RNN 参数量不会随着序列长度线性增长的重要原因。
共享参数的意义
- 模型可以处理不同长度的序列
- 参数规模相对可控
- 学到的是“序列模式”,而不是某个固定位置的规则
常见输入输出形式
RNN 可以根据任务设计成不同的输入输出结构:
| 类型 | 示例任务 | 说明 |
|---|---|---|
| One-to-One | 图像分类 | 普通前馈网络更常见 |
| One-to-Many | 图像描述生成 | 一个输入生成一个序列 |
| Many-to-One | 情感分类 | 一个序列输出一个结果 |
| Many-to-Many | 机器翻译、序列标注 | 输入序列对应输出序列 |
训练方式
RNN 的训练通常使用 通过时间的反向传播(Backpropagation Through Time, BPTT)。
它本质上是把时间展开后的 RNN 看成一个更深的网络,然后沿时间方向做反向传播。
主要步骤如下:
- 按时间顺序做前向计算,得到每个时间步的隐藏状态和输出。
- 计算总损失,损失可能来自最后一步,也可能来自每一步。
- 沿时间反向传播梯度,更新共享参数。
语言模型里的训练
例如输入序列是 ["我", "喜欢", "深度学习"],模型可以在每一步预测“下一个词”,然后把多个时间步的损失累加起来一起训练。
梯度消失与梯度爆炸
RNN 最经典的问题是:当序列很长时,梯度需要跨很多时间步传播,容易出现:
- 梯度消失(Vanishing Gradient):前面时间步的信息很难传到后面
- 梯度爆炸(Exploding Gradient):梯度值变得非常大,训练不稳定
这会导致基础 RNN 很难学习长期依赖(Long-Term Dependency)。
什么是长期依赖
指的是当前预测需要依赖很久之前的信息。
例如句子:
The keys to the cabinet ... are on the table.
模型在预测 are 时,需要记住前面真正的主语 keys,而不是被中间一串词干扰。
常见缓解方式
- 使用更稳定的门控结构,比如 LSTM、GRU
- 做梯度裁剪(Gradient Clipping)
- 合理初始化参数
- 使用较短的截断反向传播(Truncated BPTT)
LSTM
LSTM(Long Short-Term Memory)是 RNN 的重要改进版本,专门用于缓解长期依赖问题。
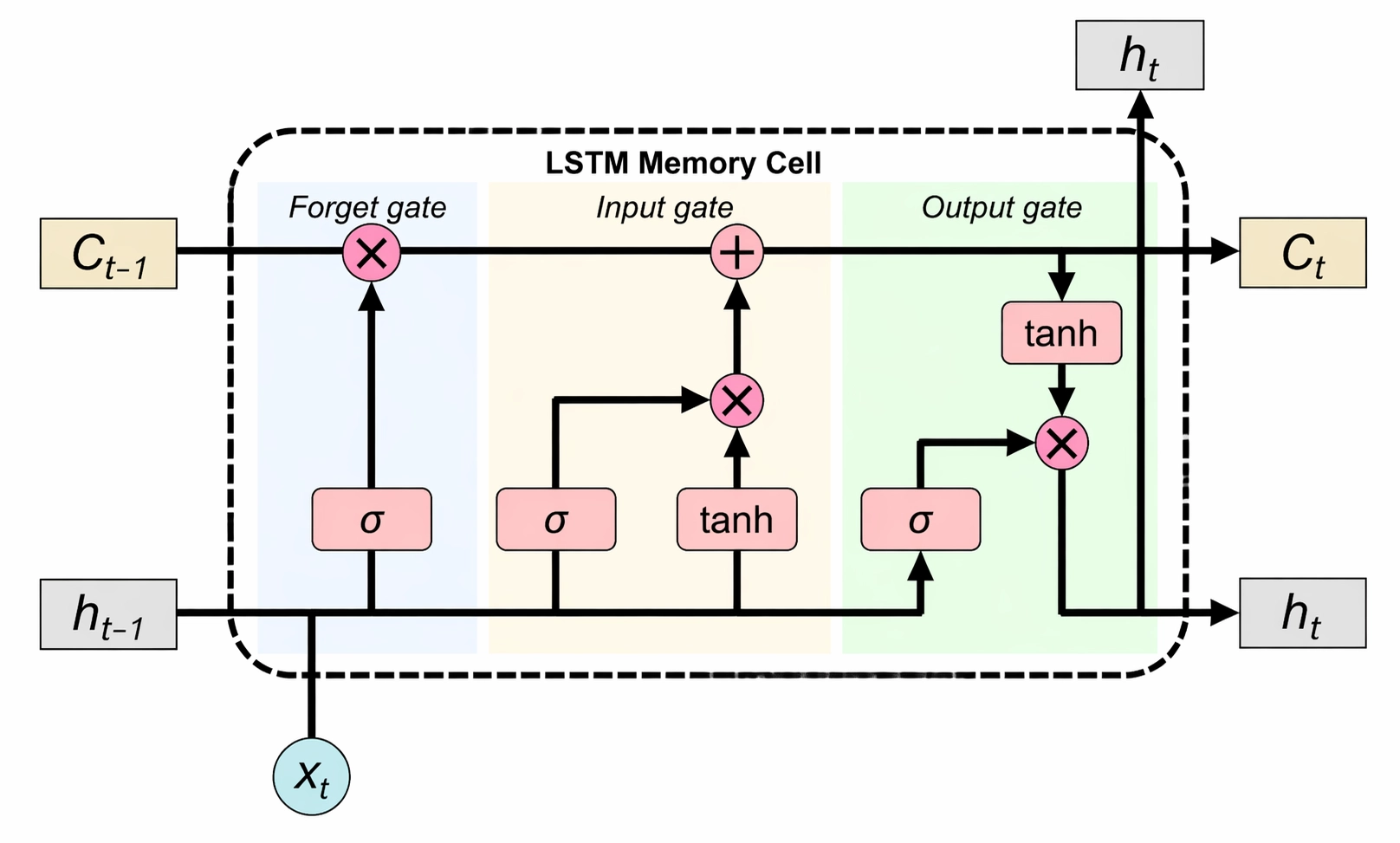
它引入了细胞状态(Cell State)和多个门(Gate)来控制信息流动:
- 遗忘门(Forget Gate):决定丢掉哪些旧信息
- 输入门(Input Gate):决定写入哪些新信息
- 输出门(Output Gate):决定输出哪些信息
遗忘门
遗忘门(Forget Gate)的作用是:决定上一时刻的细胞状态 \(C_{t-1}\) 中,哪些信息应该保留,哪些信息应该丢弃。
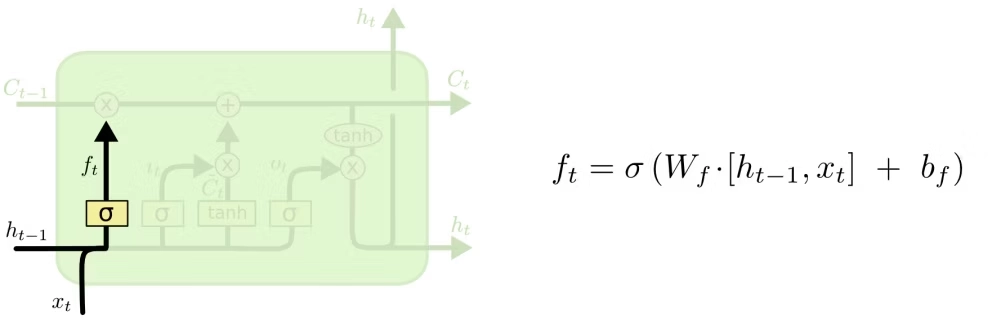
可以把它理解成一个“筛子”:
- 接近
1的部分表示尽量保留 - 接近
0的部分表示尽量忘掉
这一步很重要,因为不是所有历史信息都对当前任务有用。LSTM 先通过遗忘门清理掉无关或过时的信息,再进行后续更新。
输入门
输入门(Input Gate)的作用是:决定当前输入 \(x_t\) 和当前候选记忆中,有哪些新信息值得写入细胞状态。
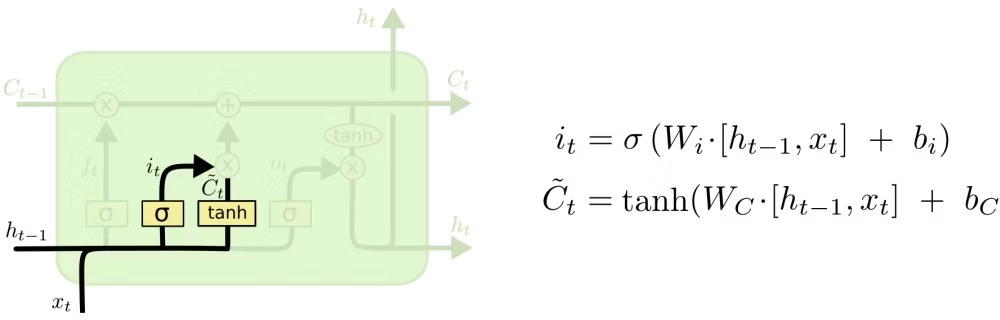
它本质上回答的是:
- 当前这一刻来了哪些新内容
- 这些新内容里哪些值得记住
因此,输入门负责“写入”过程。它让 LSTM 不会把每一步的输入都无条件塞进记忆里,而是有选择地更新状态。
输出门
输出门(Output Gate)的作用是:决定当前细胞状态中,哪些信息应该暴露为当前时刻的隐藏状态 \(h_t\),并传递给下一层或下一时间步。
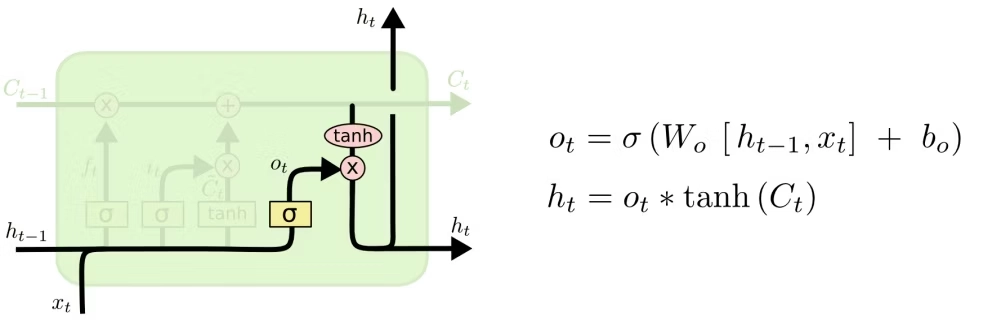
也就是说:
- 细胞状态更像是内部长期记忆
- 隐藏状态更像是当前时刻对外可见的表达
输出门控制“记住的东西里,哪些现在拿出来用”。这让 LSTM 可以保留长期信息,同时只输出当前真正需要的部分。
因此 LSTM 在很多长序列任务上比基础 RNN 更稳定。
GRU
GRU(Gated Recurrent Unit)也是常见的门控循环单元,可以看作是 LSTM 的简化版本。
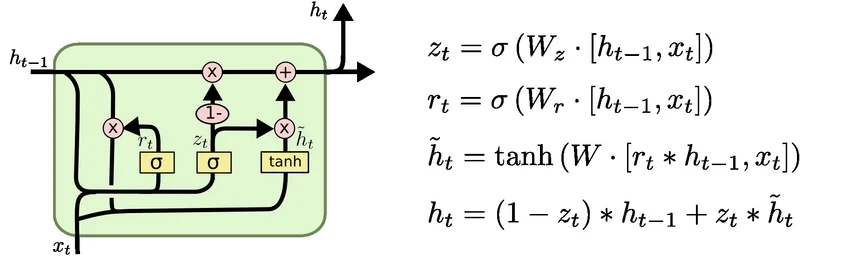
它通常包含:
- 更新门(Update Gate)
- 重置门(Reset Gate)
相较于 LSTM:
- 结构更简单
- 参数更少
- 训练速度通常更快
在不少任务上,GRU 可以用更低成本达到接近 LSTM 的效果。
RNN、LSTM、GRU 对比
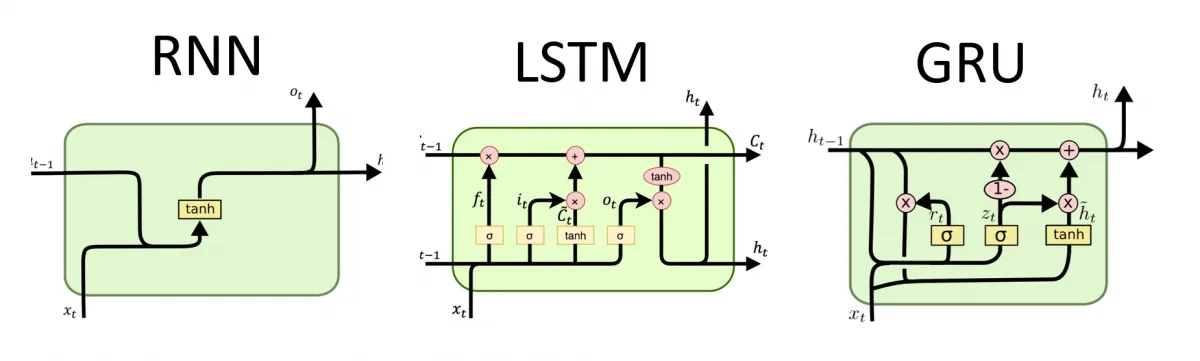
| 模型 | 特点 | 优势 | 局限 |
|---|---|---|---|
| RNN | 基础循环结构 | 简单直观 | 难处理长依赖 |
| LSTM | 带细胞状态和多个门 | 长序列建模更强 | 参数较多,计算更重 |
| GRU | 简化门控结构 | 更轻量,训练更快 | 表达能力依任务而定 |
优点与局限
-
RNN 的优点
- 天然适合处理序列数据
- 可以建模时间依赖关系
- 参数在时间步之间共享,参数量相对可控
- 是理解序列建模的基础
-
RNN 的局限
- 难以捕捉长距离依赖
- 训练难并行,时间步之间存在依赖
- 长序列训练容易不稳定
- 在很多任务上已被 Transformer 超越
适用场景
RNN 及其变体常见于以下任务:
- 语言模型
- 文本分类
- 序列标注
- 语音识别
- 时间序列预测
- 日志或用户行为序列建模