PostgreSQL
PostgreSQL 是一个功能完整的开源关系型数据库管理系统(RDBMS),通常简称为 Postgres。它以事务可靠、标准兼容、扩展能力强著称,既适合传统业务系统,也适合承载分析、地理信息、全文检索和事件数据等更复杂的场景。
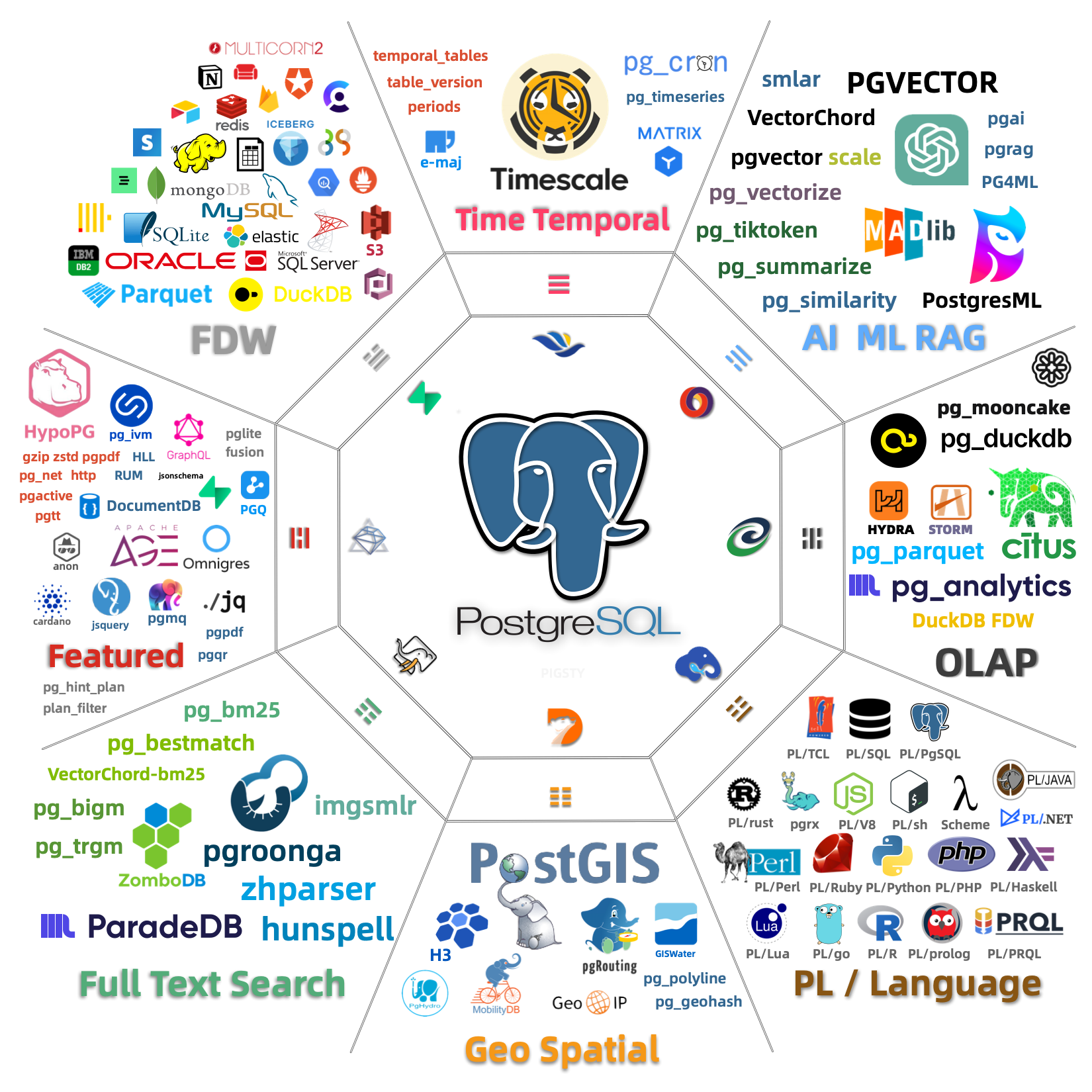
Abstract
PostgreSQL 的核心价值可以概括为三点:
- 可靠:事务、一致性、恢复机制成熟
- 强大:SQL、索引、类型系统、扩展生态完整
- 通用:既能支撑业务系统,也能覆盖更复杂的数据需求
PostgreSQL 简介
PostgreSQL 本质上是一个面向对象特性较丰富的关系型数据库,支持:
- 完整的事务处理能力(ACID)
- 丰富的 SQL 特性
- 复杂查询优化
- 多种索引类型
- JSON / JSONB
- 自定义类型、函数、扩展
PostgreSQL 凭借强大的数据建模与查询能力,早已不只是一个简单的表存储工具,更常被视为能力更全面、工程上限更高的通用型数据库基础。相较于更强调轻量和普及性的 MySQL,它通常更适合支撑复杂度更高、类型更多样的业务场景。
核心特性
强事务能力
PostgreSQL 原生支持 ACID 事务:
- Atomicity:事务要么全部成功,要么全部失败
- Consistency:事务执行前后数据保持约束一致
- Isolation:并发事务之间互不干扰
- Durability:事务提交后不会因为进程退出而丢失
这使得 PostgreSQL 很适合订单、支付、库存、账户等对一致性要求较高的系统。
MVCC 并发控制
PostgreSQL 通过 MVCC(Multi-Version Concurrency Control,多版本并发控制)实现高并发读写。
它的核心思路是:
- 更新数据时,不直接覆盖旧版本
- 读操作读取对当前事务可见的版本
- 写操作尽量减少对读操作的阻塞
这样做的好处是:
- 读写并发性能更好
- 普通查询通常不会被写事务长时间阻塞
- 更容易实现一致性读
WAL 保证持久性
PostgreSQL 使用 WAL(Write-Ahead Logging,预写式日志)保证数据可靠性。
写入流程可以粗略理解为:
- 先把变更写入 WAL
- 再将数据页刷回磁盘
- 崩溃恢复时基于 WAL 重放
WAL 也是主从复制、时间点恢复(PITR)等能力的基础。
SQL 能力完整
PostgreSQL 对 SQL 标准支持较好,常见高级能力包括:
CTE与递归查询- 窗口函数
- 复杂
JOIN - 视图与物化视图
- 子查询与集合操作
- 触发器、存储过程、函数
对于数据平台、后台管理系统、复杂报表系统来说,这些能力非常实用。
数据类型支持
PostgreSQL 不只适合传统二维表,还支持很多更灵活的数据结构。
常见类型包括:
- 数值类型:
integer、bigint、numeric - 字符类型:
text、varchar - 时间类型:
timestamp、date - 布尔类型:
boolean - 数组类型:
text[]、integer[] - JSON 类型:
json、jsonb - UUID:
uuid - 地理空间:结合
PostGIS
其中最常被提到的是 jsonb:
- 支持半结构化数据存储
- 可对 JSON 字段建立索引
- 适合配置、事件属性、动态表单等场景
这让 PostgreSQL 在很多场合可以同时覆盖“关系型数据 + 文档型数据”的需求。
常见索引类型
PostgreSQL 的索引能力非常强,不同数据结构可以选择不同索引。
| 索引类型 | 典型用途 |
|---|---|
B-Tree |
默认索引,适合等值查询、范围查询、排序 |
Hash |
适合等值匹配,实际使用较少 |
GIN |
适合 jsonb、数组、全文检索 |
GiST |
适合地理空间、范围类型、近似匹配 |
BRIN |
适合超大表、追加写入、按时间有序的数据 |
一般情况下:
- 普通主键、唯一键、状态字段查询优先用
B-Tree jsonb字段检索优先考虑GIN- 时序大表可以评估
BRIN
索引不是越多越好
索引会提升查询速度,但也会增加写入成本、占用更多磁盘,并影响 INSERT / UPDATE / DELETE 性能。设计索引时应以查询模式为依据,而不是“把所有字段都建索引”。
PostgreSQL 生态
PostgreSQL 之所以长期流行,一个重要原因是生态成熟。
常见生态组件包括:
psql:命令行客户端pg_dump/pg_restore:备份恢复PostGIS:地理空间扩展pgvector:向量检索扩展- 流复制 / 逻辑复制:高可用与数据同步
- 各类 ORM 与驱动:Python、Go、Java、Node.js 等
pgvector
尤其是 pgvector 的流行,让 PostgreSQL 在 AI 应用里也更常见,可以直接承载:
- 向量存储
- 元数据过滤
- 结构化业务数据
适用场景
PostgreSQL 适合的场景很多,尤其适合作为一个通用型主数据库来使用。常见情况包括:
- 业务系统主库
- 用户、订单、账户、库存等事务型系统
- 中后台与报表系统
- 存储带动态属性的业务数据(
jsonb) - 全文检索
- GIS / 地图类业务(配合
PostGIS) - 中小规模数据平台或实时服务
在很多中后台系统里,PostgreSQL 往往可以“一库多用”:
- 既做 OLTP
- 也做部分统计查询
- 还能承载文档字段和搜索能力
选型建议
如果符合下面的大多数条件,PostgreSQL 通常是一个稳妥选择:
- 需要可靠事务
- 查询逻辑较复杂
- 希望尽量使用标准 SQL
- 需要
jsonb、全文检索、地理空间或向量扩展 - 不希望系统早期就拆分太多中间件
不适用场景
如果存在以下情况,PostgreSQL 通常不适合使用:
- 极致的海量分析查询
- PB 级数据仓库
- 专门的日志分析或列式计算
那通常应该考虑 ClickHouse、DuckDB、Trino 等更偏分析型的系统,而不是单独依赖 PostgreSQL。