Faiss
FAISS(Facebook AI Similarity Search)是由 Facebook AI Research 开发的高性能相似性搜索库,专门用于处理海量向量的高效相似度检索与聚类问题。 支持 CPU 和 GPU,适合大规模向量搜索任务,如推荐系统、搜索引擎、图像相似搜索等。

简介
Faiss 是一个用于高效相似性搜索和密集向量聚类的库。它包含了一系列用于在任意规模的向量集合中进行搜索的算法,甚至支持处理无法完全装入内存的大型数据集。 Faiss 还提供了评估与参数调优的辅助工具。该库由 C++ 编写,并为 Python 提供了完整的绑定。部分最常用的算法还提供 GPU 实现。
高级功能支持
除了基础的相似度检索功能之外,Faiss 还具备如下高级特性:
- 返回 第 2、3…k 个最近邻居,而不仅仅是最邻近的一个;
- 支持 批量搜索多个向量,许多索引类型在批处理下搜索速度更快;
- 精度与性能的权衡:例如,可以接受 10% 的搜索错误率以换取 10 倍的速度或内存节省;
- 支持 最大内积(Inner Product)搜索:\(argmax_i⟨x,x_i⟩\),并对其他距离度量(如 L1、Linf)提供有限支持;
- 执行 范围搜索:返回与查询向量在给定半径内的所有元素;
- 将索引 保存在磁盘 而不是内存中;
- 支持 二进制向量索引;
- 可根据向量的 ID 实现 对部分向量的忽略(谓词过滤)。
PQ 及其技术体系发展脉络
下图(摘自论文《A Survey of Product Quantization》)梳理了 PQ(Product Quantization)技术的主要发展脉络与相关领域研究:
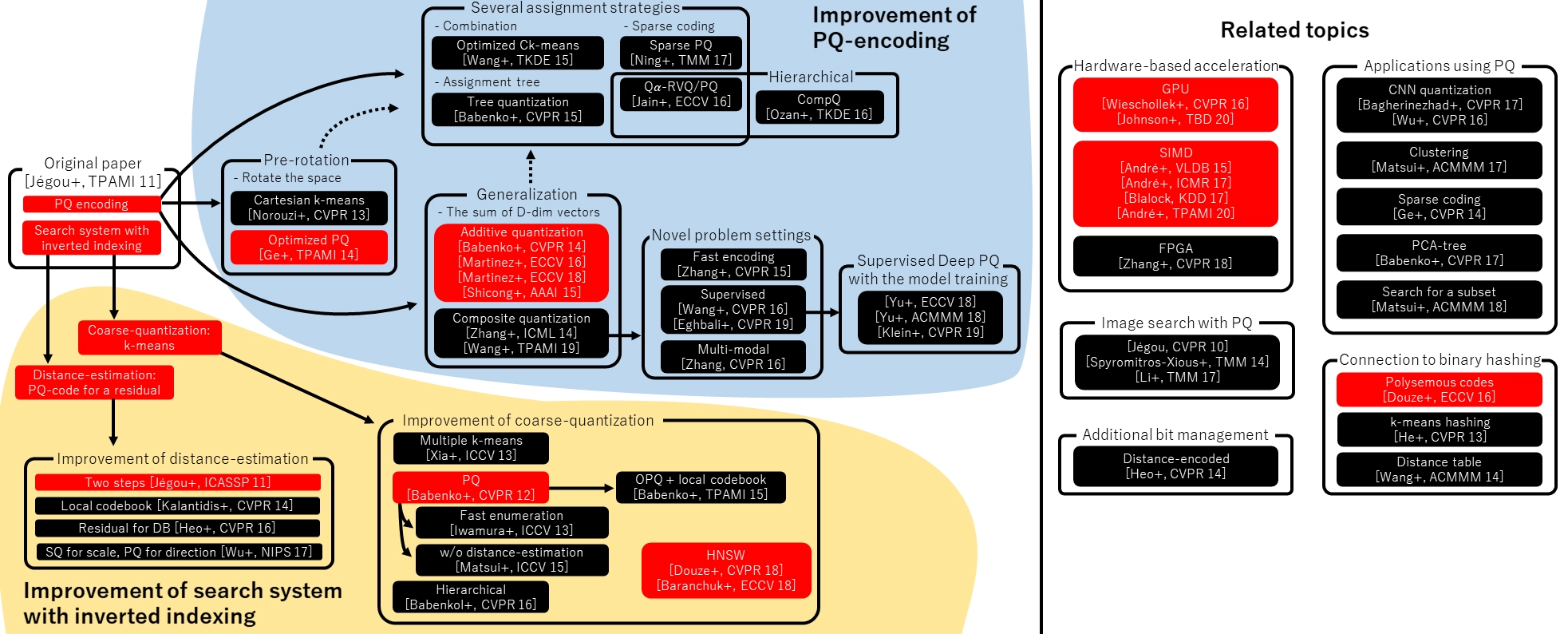
Faiss 的核心贡献(红色区域)
- PQ 编码(Product Quantization) 及倒排索引(Inverted Index)是 Faiss 的起点与基础技术。
- 这部分主要源自 Jégou 等人在 TPAMI 2011 上的工作,为后续大规模向量搜索的高效实现奠定了基础。
相关话题
- 硬件与加速技术
- GPU 并行加速(Johnson+)
- SIMD 快速选择(André+)
- FPGA 实现
- PQ 技术的多种应用
- CNN 向量量化与压缩
- 聚类、稀疏编码、PCA-tree 等
- 子集检索优化
- 二值哈希相关技术
- Polysemous Codes(Douze+, ECCV 2016):Faiss 支持的二值哈希过滤加速方法
- 相关技术还包括 k-means 哈希、距离查找表(distance table)
PQ 编码的改进与演化(蓝色区域)
- 预旋转(Pre-rotation)
- 空间旋转以提高量化表现,如 Cartesian k-means、Optimized PQ 等。
- 分配策略改进(Assignment Strategies)
- 组合分配(如 Optimized Ck-means)
- 树状分配(Tree Quantization)
- 稀疏 PQ 编码(Sparse PQ)
- 泛化/扩展
- 加性量化(Additive Quantization,AQ)
例如:Babenko+ (CVPR 2014), Martinez+ (ECCV 2016/2018), Shicong+ (AAAI 2015) - 复合量化(Composite Quantization,CQ)
- 加性量化(Additive Quantization,AQ)
- 深度学习方向
- 监督式 Deep PQ(Yu+, Klein+ 等)
通过以上梳理,可以快速了解 Faiss 及其背后 PQ 系列核心方法的技术谱系、改进方向和相关主题。