神经网络(Neural Network)
Abstract
神经网络(Neural Network, NN)是一种受生物神经系统启发的机器学习模型,主要用于模式识别、数据预测、自动特征提取等任务。 它由多个层级的神经元(Neurons) 组成,通过学习数据中的模式来完成分类、回归等任务。
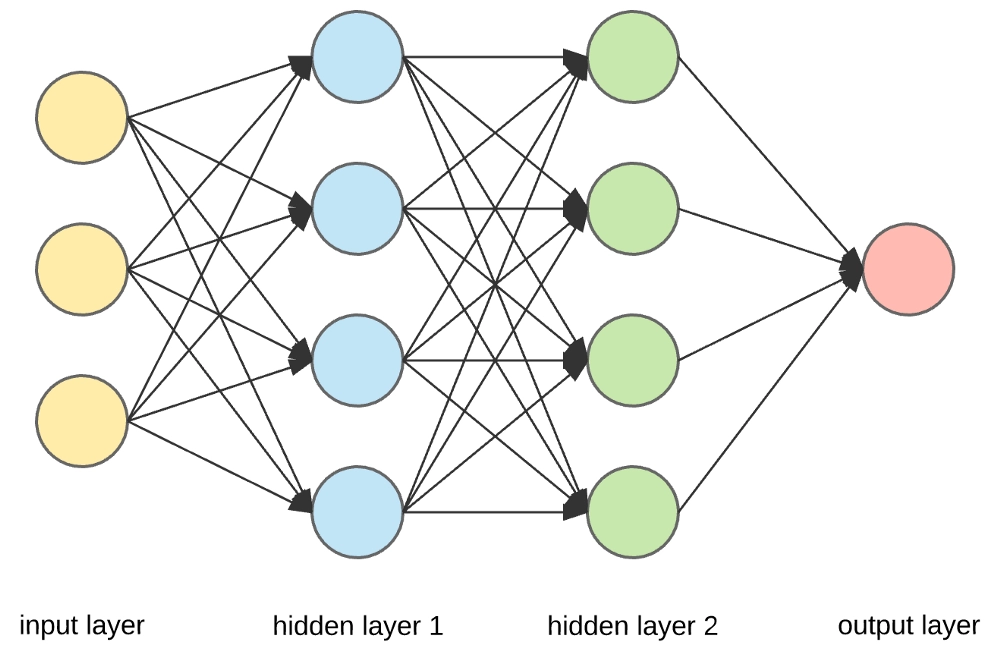
基本结构
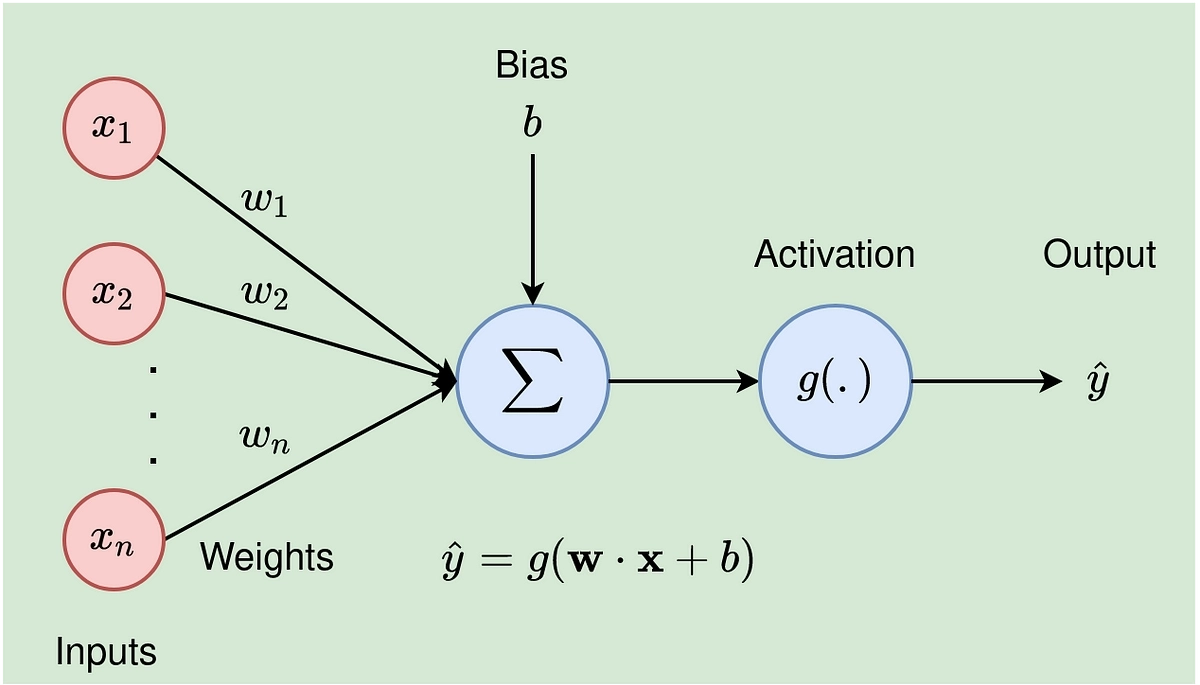
神经元(Neuron)
神经元是神经网络的最小计算单元。
由以下几个部分组成:
- 输入(Input):从前一层接收数据
- 权重(Weights):调整输入的影响程度
- 偏置(Bias):用于调整计算结果
- 激活函数(Activation Function):引入非线性
- 输出(Output):传递到下一层
层(Layer)
神经网络通常由以下几种层组成:
- 输入层(Input Layer):接受数据,不执行计算
- 隐藏层(Hidden Layers):执行计算,通过权重和激活函数进行特征提取
- 输出层(Output Layer):生成最终预测结果
前向传播
前向传播(Forward Propagation, FP)是神经网络从输入到输出的计算过程,主要步骤如下:
- 输入数据通过神经元加权求和:\(z=\sum_{i=1}^{n} (w_i \cdot x_i) + b\)
- 通过激活函数计算输出:\(a=f(z)\)
- 结果传递到下一层,直到输出层生成最终结果。
反向传播
神经网络的训练主要依赖反向传播算法(Backward Propagation, BP),其核心步骤如下:
- 前向传播:计算神经网络的输出值。
- 计算损失:使用损失函数衡量预测值与真实值之间的误差。
- 反向传播:利用链式法则计算梯度,更新权重和偏置。
- 梯度下降:使用优化算法(如 SGD、Adam)调整参数,使损失最小化。
常见损失函数:
- 均方误差(MSE)(回归问题)
- 交叉熵损失(Cross-Entropy Loss)(分类问题)
激活函数
激活函数(Activation Function)是神经网络中引入非线性的一种函数。
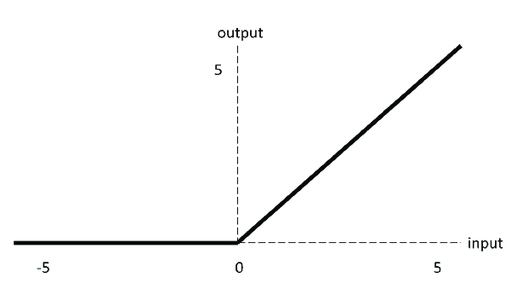
ReLU
ReLU(Rectified Linear Unit)公式为:
- 适用场景:
- CNN(卷积神经网络)
- DNN(深度神经网络)
-
优点
- 计算简单,收敛快
- 解决了 Sigmoid 和 Tanh 的梯度消失问题
- 适用于深度神经网络(DNN)
-
缺点
- 可能出现 “ReLU 死亡”(神经元恒为 0,不更新)
- 负数区域的梯度为 0,可能影响学习
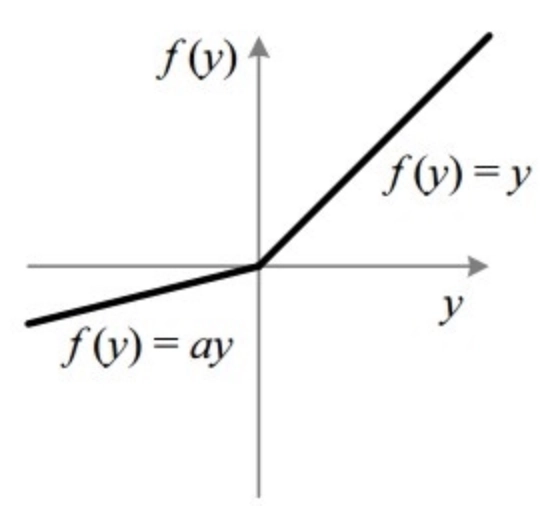
Leaky ReLU
Leaky ReLU(Leaky Rectified Linear Unit)公式为:
其中 α 是一个小正数(通常为 0.01)。
- 适用场景:
- CNN(卷积神经网络)
- DNN(深度神经网络)
-
优点
- 解决了 ReLU 的 死亡问题
- 允许负数部分保留少量信息
-
缺点
- 需要手动调节 α
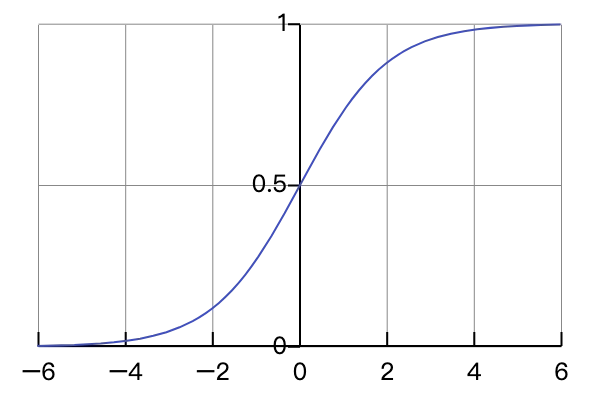
Sigmoid
公式:
- 适用场景:
- 二分类任务(如 Logistic Regression)
-
优点
- 输出范围 \([0, 1]\),可用于概率计算
- 适用于二分类问题
-
缺点
- 容易出现 梯度消失
- 计算复杂度较高
- 不适合深度网络
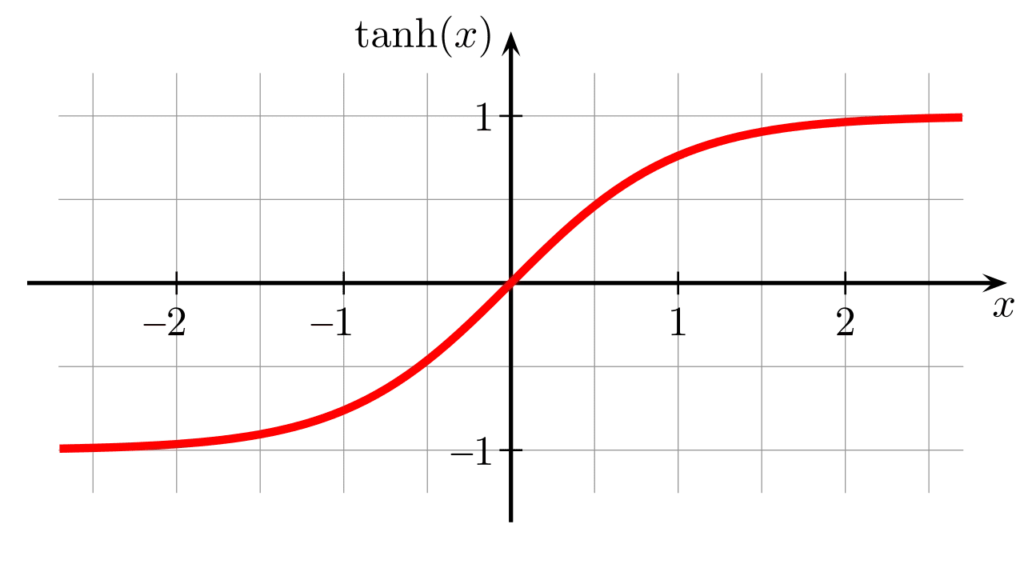
Tanh
公式:
- 适用场景:
- RNN(循环神经网络)
-
优点
- 输出范围 \([-1, 1]\),比 Sigmoid 更平衡
- 梯度范围较大,比 Sigmoid 更适合深度学习
-
缺点
- 计算复杂度较高
- 深层网络仍可能出现 梯度消失
Softmax
Softmax 通常应用于神经网络输出层,尤其适合多分类任务。 它能够将网络输出的原始向量“压缩”成一个概率分布,各个分量的取值范围 \([0, 1]\),且所有分量之和为 1。
Note
严格来说,Softmax 不是激活函数,而是一种归一化函数(normalization function)。
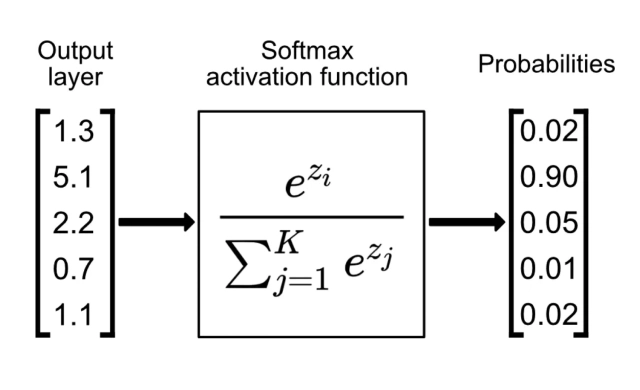
对于一个输入向量 \(z = [z_1, z_2, ..., z_n]\),Softmax 计算公式如下:
- \(z_i\) 是输入向量中的第 i 个元素。
- \(e^{z_i}\) 计算指数函数,确保所有输出都是正数。
- \(\sum_{j=1}^{n} e^{z_j}\)是所有指数值的和,起到归一化作用,使得输出总和为 1。
-
优点
- 归一化概率输出,适用于多分类任务
- 可微性强,易于优化
- 具有概率解释性,输出值可直接用于分类决策
- 放大大值影响,提高分类置信度
-
缺点
- 计算复杂度较高,涉及指数运算和归一化
- 对异常值敏感,可能导致梯度消失或梯度爆炸
- 类别之间互斥,不适用于多标签分类
适用场景:
- 图像分类(CNN 终层)
- 自然语言处理(Transformer、RNN 终层)
- 注意力机制(计算权重分布)
- 强化学习(策略梯度方法)
Sigmoid vs Softmax
| 比较项 | Sigmoid | Softmax |
|---|---|---|
| 主要用途 | 二分类 / 多标签分类 | 多分类(单标签) |
| 输出范围 | (0,1) | 归一化概率分布(所有类别之和为 1) |
| 适用情况 | 每个类别单独计算概率 | 归一化后选最大概率类别 |
| 梯度问题 | 易梯度消失 | 受类别分布影响大 |
| 输出神经元 | 只处理单个神经元输出 | 处理多个神经元输出 |
训练神经网络
神经网络的训练通常包括以下步骤:
- 初始化权重和偏置(随机初始化)
- 前向传播计算输出
- 计算损失函数
- 反向传播计算梯度
- 优化器更新参数
- 循环迭代直到收敛
典型的神经网络架构
| 架构名称 | 英文缩写 | 特点与主要应用 |
|---|---|---|
| 前馈神经网络 | FNN | 最基本的神经网络,数据从输入层到输出层单向流动。 |
| 卷积神经网络 | CNN | 适用于图像处理,利用卷积层提取特征。 |
| 递归神经网络 | RNN | 适用于序列数据,如文本、语音处理。 |
| 生成对抗网络 | GAN | 由生成器和判别器组成,用于生成数据,如图像合成。 |
| 变分自编码器 | VAE | 一种概率生成模型,适用于无监督学习。 |
现代优化方法
为了提高训练效果,通常使用以下优化方法:
Adam
自适应矩估计(Adaptive Moment Estimation, Adam)是一种先进的梯度下降优化算法,它结合了动量(Momentum)和均方根传播(RMSprop)的思想,自适应调整学习率,使神经网络训练更加高效和稳定。
Batch Normalization
批量归一化(Batch Normalization, BN)是一种在训练过程中对神经网络层输入进行归一化的技术,旨在加速训练过程、提高模型稳定性和泛化能力。
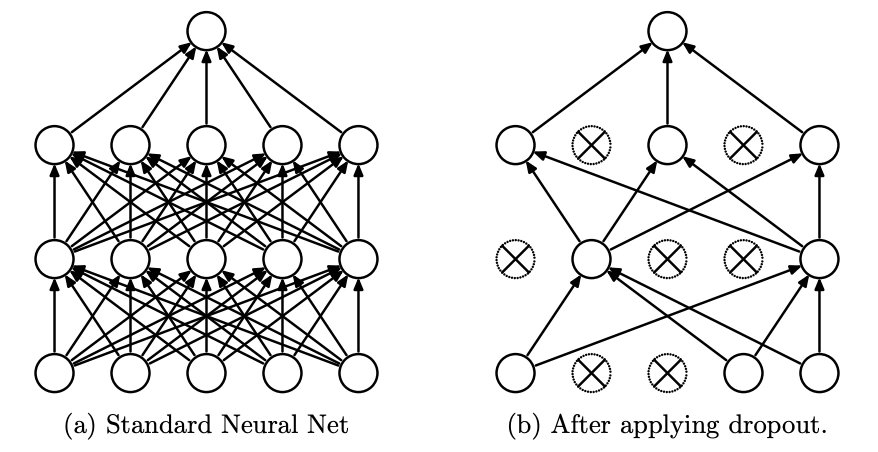
Dropout
Dropout 是一种在训练过程中随机丢弃部分神经元的技术,旨在防止过拟合。
Data Augmentation
数据增强(Data Augmentation)是一种通过对训练数据进行随机变换来生成新样本的技术,可以有效提高模型的泛化能力,特别适用于深度学习。