KD-Tree
KD-Tree(K-Dimensional Tree)是一种用于组织低维向量空间的树形数据结构,适合处理小规模、高精度的向量检索任务。
📌 原理简介
KD-Tree 是一种空间划分树(space partitioning tree),通过递归地选择某一维度将向量空间划分为左右子区域,构建出一棵二叉树。
构建过程大致如下:
- 选择当前划分维度(如第
k维); - 按该维度对所有点排序,选择中位数作为当前节点;
- 左子树存储小于中位数的点,右子树存储大于中位数的点;
- 对子节点递归重复 1~3 步。
为了方便理解,我们举一个 k=2 时的例子。
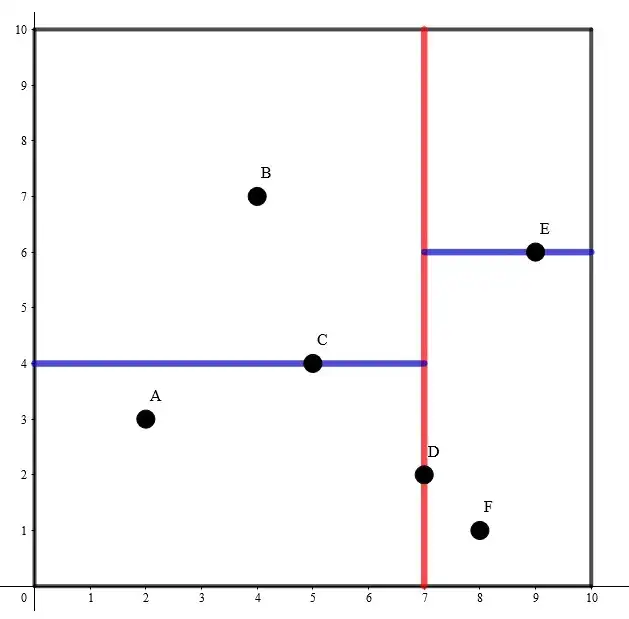
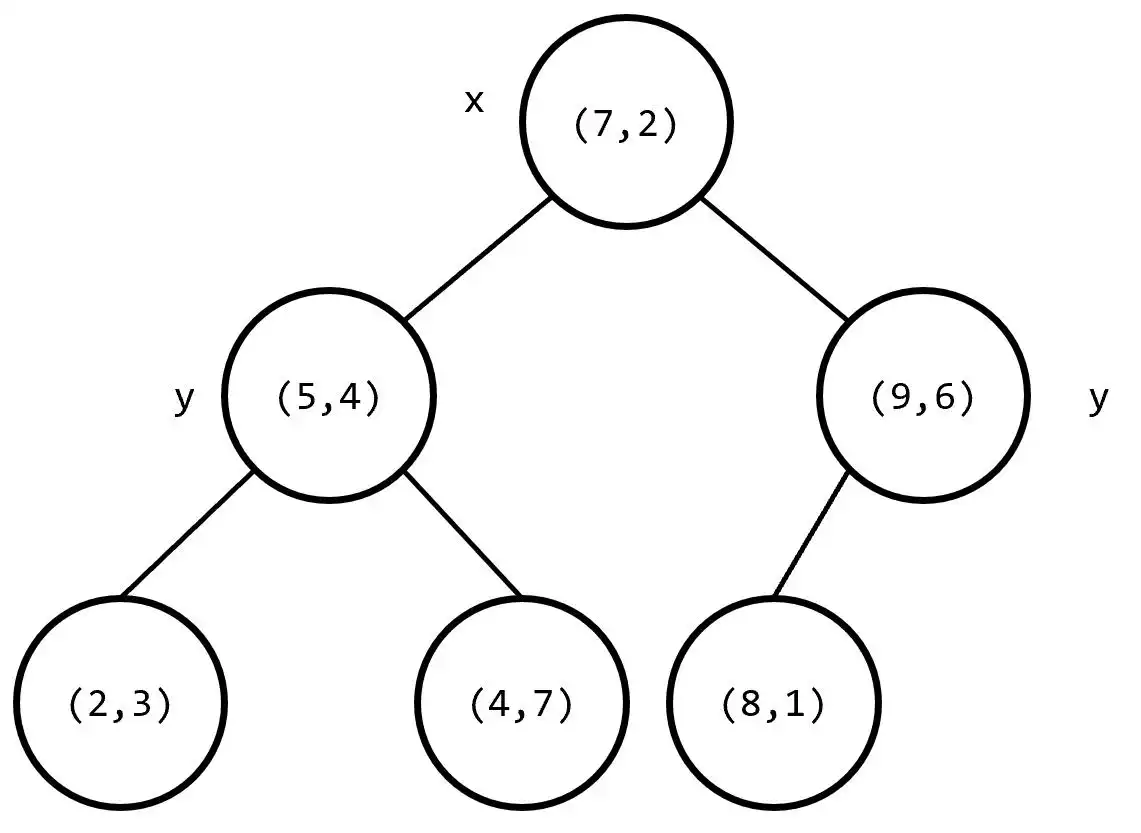
✏️ 查询过程
在查询过程中,KD-Tree 会沿树结构从上至下查找与目标向量最接近的区域,然后进行“回溯”,检查可能存在更近点的其他子区域。
Note
KD-Tree 是精确检索结构,但为提高速度也可设定近似参数(如限制回溯深度)。
✅ 优点
- 查询速度远快于线性扫描(在低维空间);
- 可用于精确最近邻(NN)或近似最近邻(ANN);
- 实现简单,库支持广泛(如
scikit-learn、FLANN)。
⚠️ 局限性
- 不适用于高维向量(维度 >20 时性能迅速下降,称为“维度灾难”);
- 样本分布不均时,树可能失衡,导致退化为线性搜索;
- 对于大规模、高维数据,推荐使用图或量化类索引。
🧪 示例(scikit-learn)
from sklearn.neighbors import KDTree
import numpy as np
# 构造数据
data = np.random.random((1000, 5)) # 1000 个 5 维向量
tree = KDTree(data, leaf_size=40)
# 查询最近邻
query = np.random.random((1, 5))
dist, ind = tree.query(query, k=3)
print("最近邻索引:", ind)
print("距离:", dist)