Product Quantization(PQ)
背景
问题:大规模向量相似度搜索(Vector Similarity Search)需要大量内存。
- 例如:1M 条稠密向量(128 维 float32)可占用数 GB 内存。
- 高维数据和数据集规模增加,内存需求迅速变得不可控。
目标:减少内存占用 + 提高检索速度。
PQ 优势(Pinecone 测试):
- 内存减少 97%
- 检索速度提升 5.5x
- IVF+PQ 索引在精度不下降的情况下,搜索速度提升了 16.5 倍, 总体速度提升了 92 倍
什么是量化(Quantization)
定义:将数据映射到一个更小的、有限的取值集合(符号化表示)。
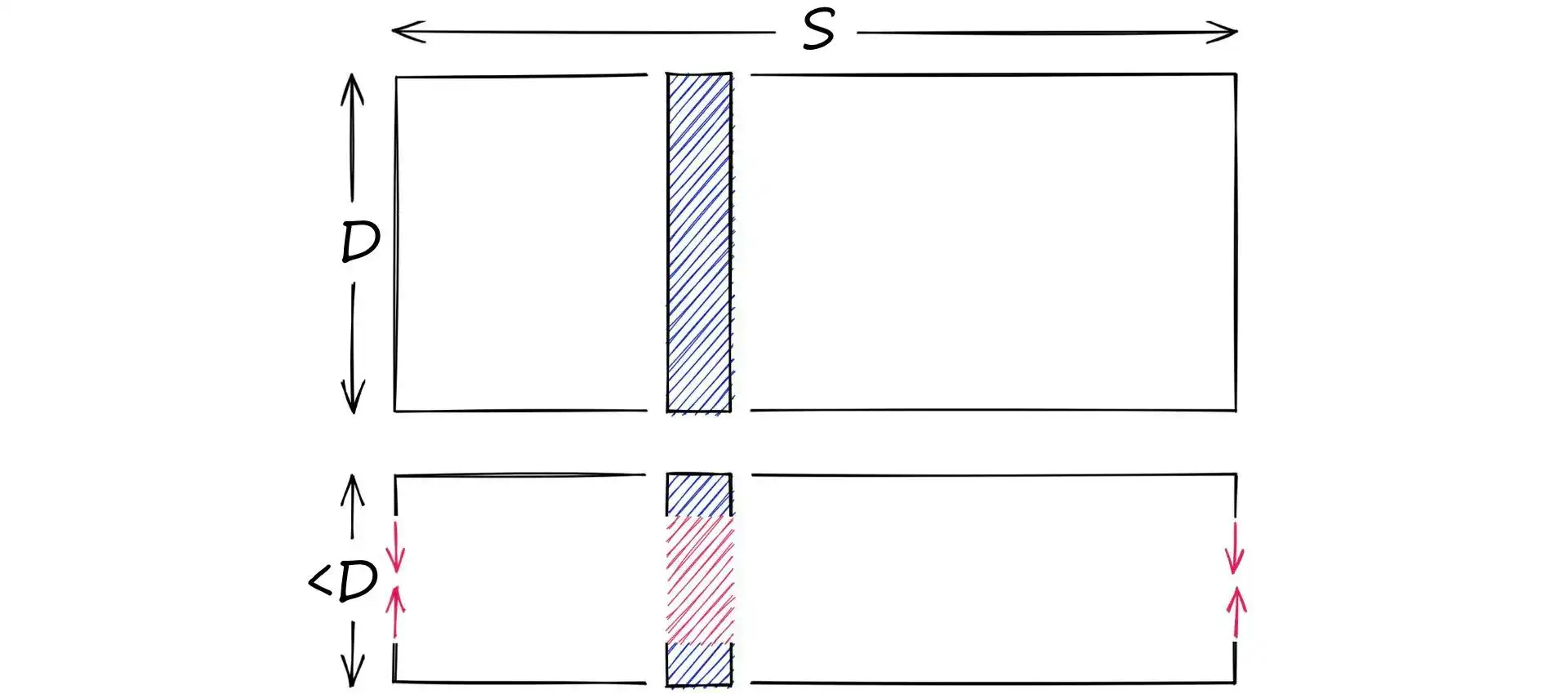
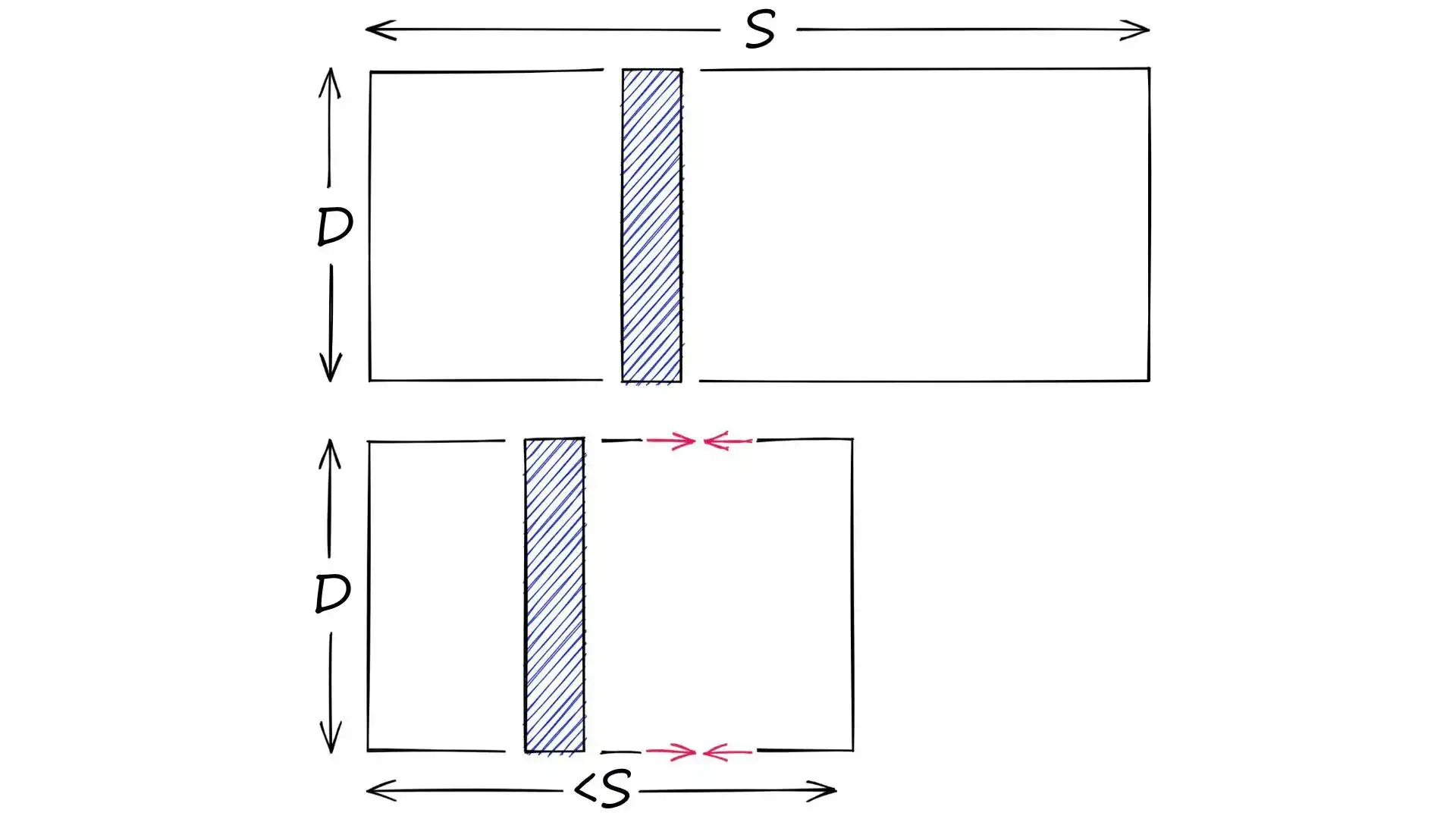
量化和降维区别:
- 降维:减少维度 D,取值范围 S 不变
- 量化:不改变维度 D,缩小取值范围 S
方式:
-
聚类:用有限个质心(centroids)近似表示无限可能的向量
-
符号化表示可为:
- 质心(PQ 的方式)
- 二进制码(如 LSH)
为什么用 PQ
内存优化
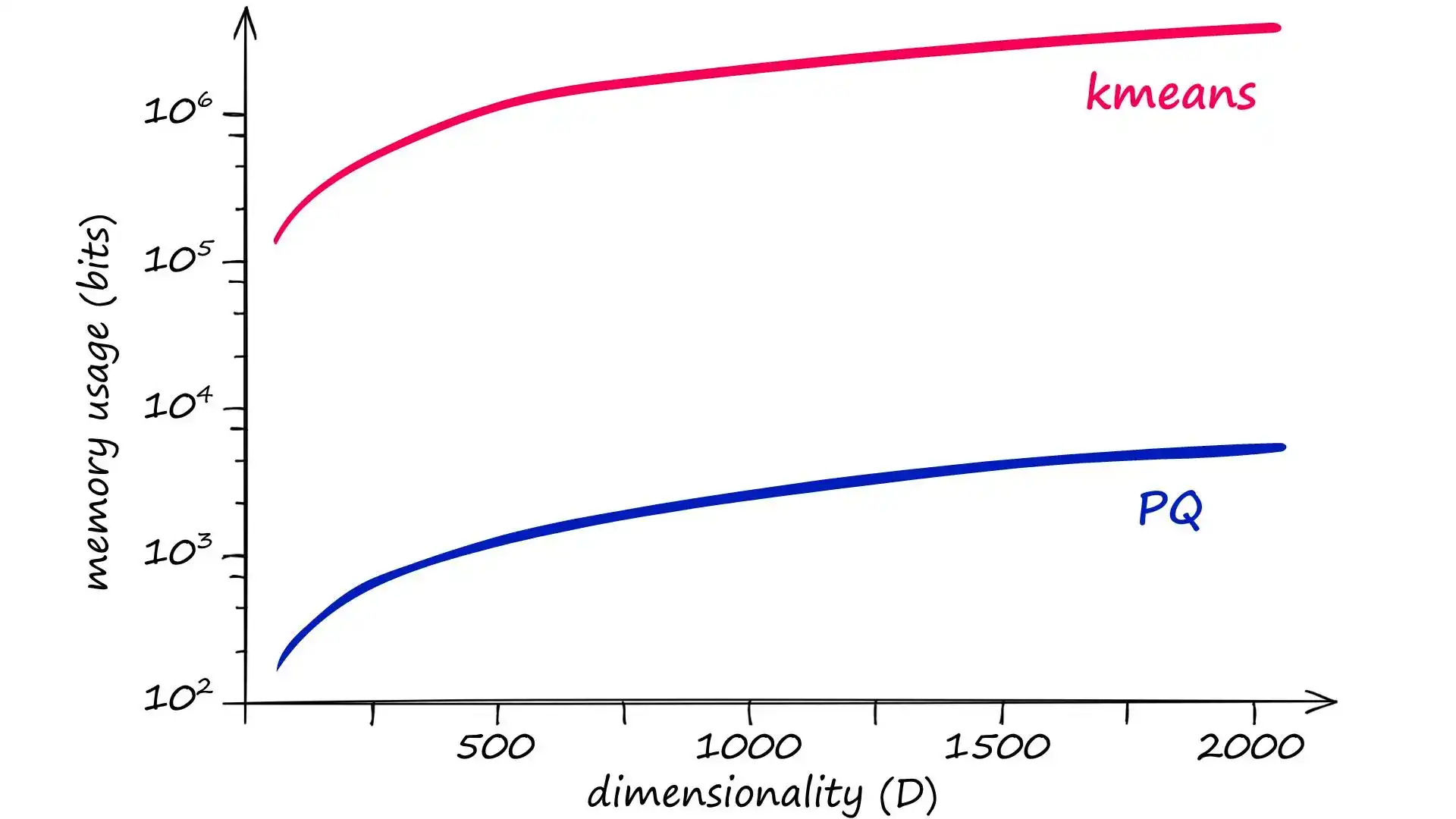
- 普通 k-means 量化内存/计算复杂度:\(k \times D\)
- PQ 把向量切成 m 段,每段用一个子量化器,中心数设为 \(k^{*}=k^{1/m}\)(保证组合码字数 \((k^{*})^m=k\))。总体内存/计算复杂度:
\[
m \times k^{*} \times D^{*}
= m \times k^{1/m} \times \frac{D}{m}
= k^{1/m} \times D
\]
符号说明
- \(D\):向量维度
- \(k\):总质心数
- \(m\):子向量数量(subvectors)
- \(k^{*} = k^{1 \over m}\)
- \(D^{*} = D / m\)
Tip
示例(k = 2048, m = 8, D = 128):
- k-means:2048 × 128 = 262,144
- PQ:\((2048^{1/8}) \times 128 \approx 332\)(显著减少)
训练数据需求
- 普通量化(不分块):通常需要 数倍于 \(k\) 的样本数来稳定训练量化器。
- 使用 PQ(分块训练):每个子量化器只在 \(D/m\) 维子空间训练。经验上,每个子量化器所需样本数可按 数倍于 \(\tilde{k}\) 估算,其中 \(\tilde{k} \approx k/m\)
别混淆 \(k^{*}\) 与 \(\tilde{k}\)
- \(k^{*} = k^{1/m}\):编码/查询阶段的精确组合关系,保证 \((k^{1/m})^m = k\)。
- \(\tilde{k} \approx k/m\):训练阶段的经验近似,估算分块后每个子量化器的样本需求。
PQ 工作原理
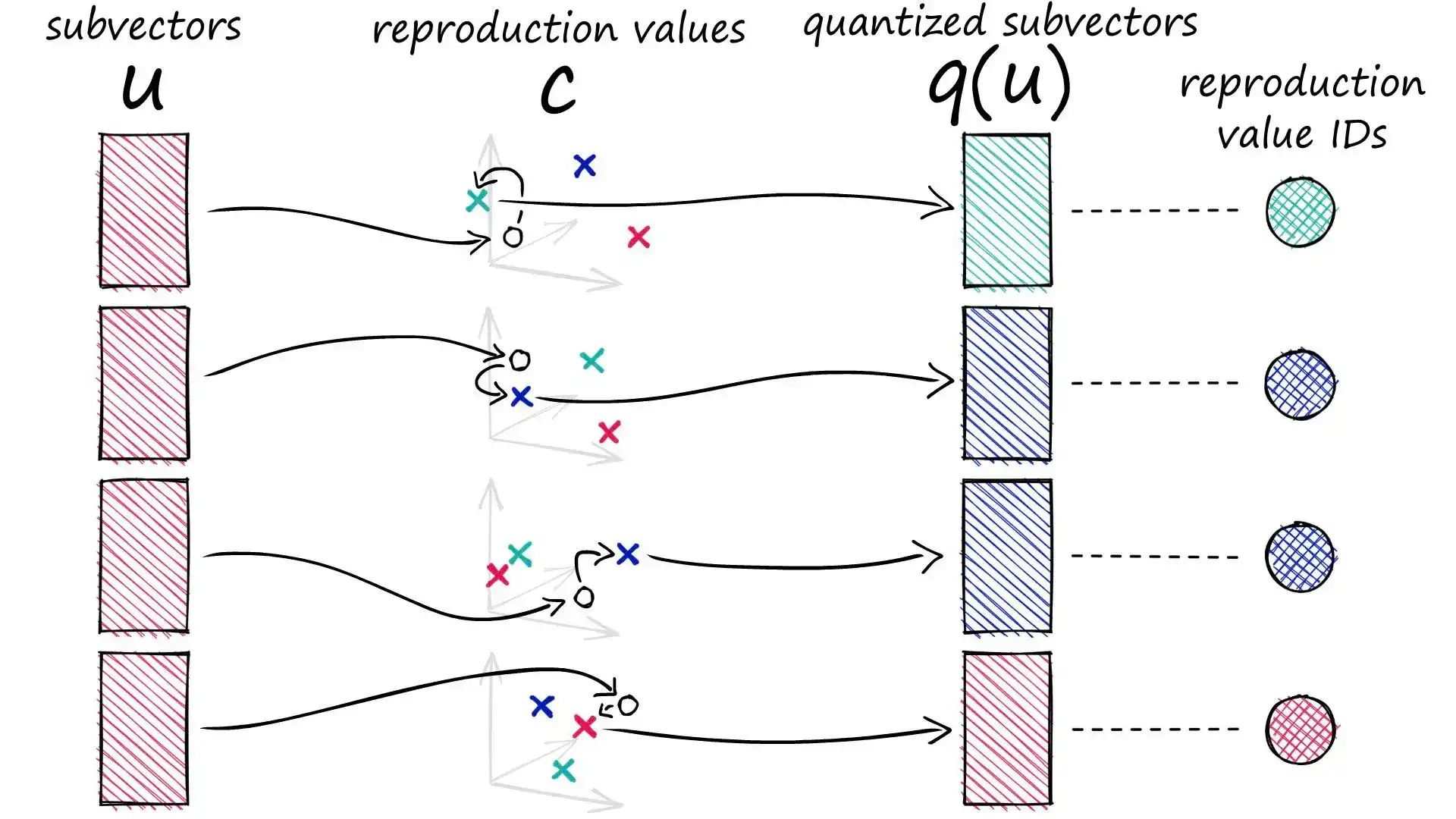
Product Quantization (PQ) 流程:
- 拆分向量:将高维向量按等长分块,得到多个子向量(subvectors)。
- 子空间聚类:对每个子向量空间(subspace)分别做聚类,得到一组质心(centroids,也称 reproduction values)。
- 替换为质心 ID:用质心 ID 替代原始子向量(ID 对应一个质心),得到一个小得多的 ID 向量。
- 压缩存储:原本需要存储 \(D\) 维的浮点数,现在只需存储 \(m\) 个整数 ID,内存占用大幅减少。

拆分向量
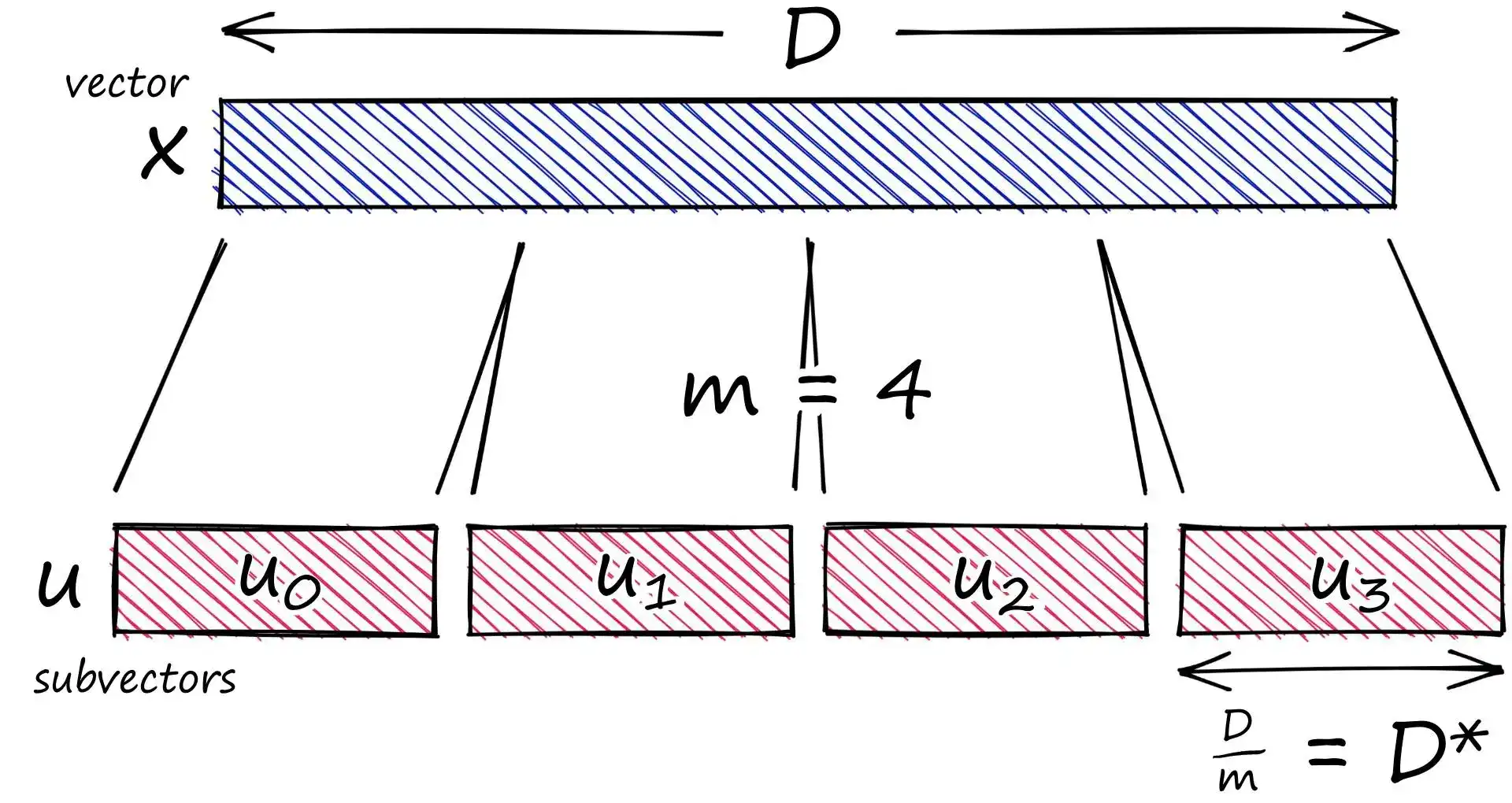
x = [1, 8, 3, 9, 1, 2, 9, 4, 5, 4, 6, 2]
m = 4
D = len(x)
assert D % m == 0
D_ = D // m # 每个子向量长度 D*
u = [x[row:row+D_] for row in range(0, D, D_)]
# u = [[1, 8, 3], [9, 1, 2], [9, 4, 5], [4, 6, 2]]
子空间聚类
假设我们选择总质心数 \(k = 32\),每个子空间分配 \(k^{*} = k/m = 8\) 个质心。
Note
示例中使用的 \(k^{*} = k/m\) 是平均分配质心数的简化做法,方便代码演示。理论上,若要求组合码字总数为 \(k\),应取 \(k^{*} = k^{1/m}\)。
from random import randint
k = 2**5 # 总质心数
k_ = k // m # 每个子空间质心数
c = []
for j in range(m):
c_j = []
for i in range(k_):
# 随机生成质心(此处简化,真实情况应为训练得到)
c_ji = [randint(0, 9) for _ in range(D_)]
c_j.append(c_ji)
c.append(c_j)
替换为质心 ID
def euclidean(v, u):
return sum((x - y) ** 2 for x, y in zip(v, u)) ** 0.5
def nearest(c_j, u_j):
nearest_idx, distance = None, float('inf')
for i in range(k_):
new_dist = euclidean(c_j[i], u_j)
if new_dist < distance:
nearest_idx, distance = i, new_dist
return nearest_idx
ids = [nearest(c[j], u[j]) for j in range(m)]
# ids = [1, 1, 2, 1]
用 ID 恢复近似向量
q = []
for j in range(m):
c_ji = c[j][ids[j]]
q.extend(c_ji)
# q = [1, 7, 7, 6, 3, 6, 7, 4, 4, 3, 9, 6]
压缩效果
| 向量表示 | 维度 | 每维位数 | 总位数 (bits) | 占用比例 |
|---|---|---|---|---|
| 原始 (float32) | 128 | 32 | 4096 | 100% |
| PQ (8×8-bit) | 8 | 8 | 64 | 1.56% |