向量检索概览
向量搜索(Vector Search)是一种基于语义相似性的检索技术,它通过将文本、图像、音频等非结构化数据转化为高维向量,并计算向量之间的相似度,从而实现更智能、更精准的信息检索。与传统的关键词匹配不同,向量搜索能够捕捉内容背后的语义关系,广泛应用于自然语言处理、推荐系统、图像识别以及大语言模型的检索增强生成等场景。
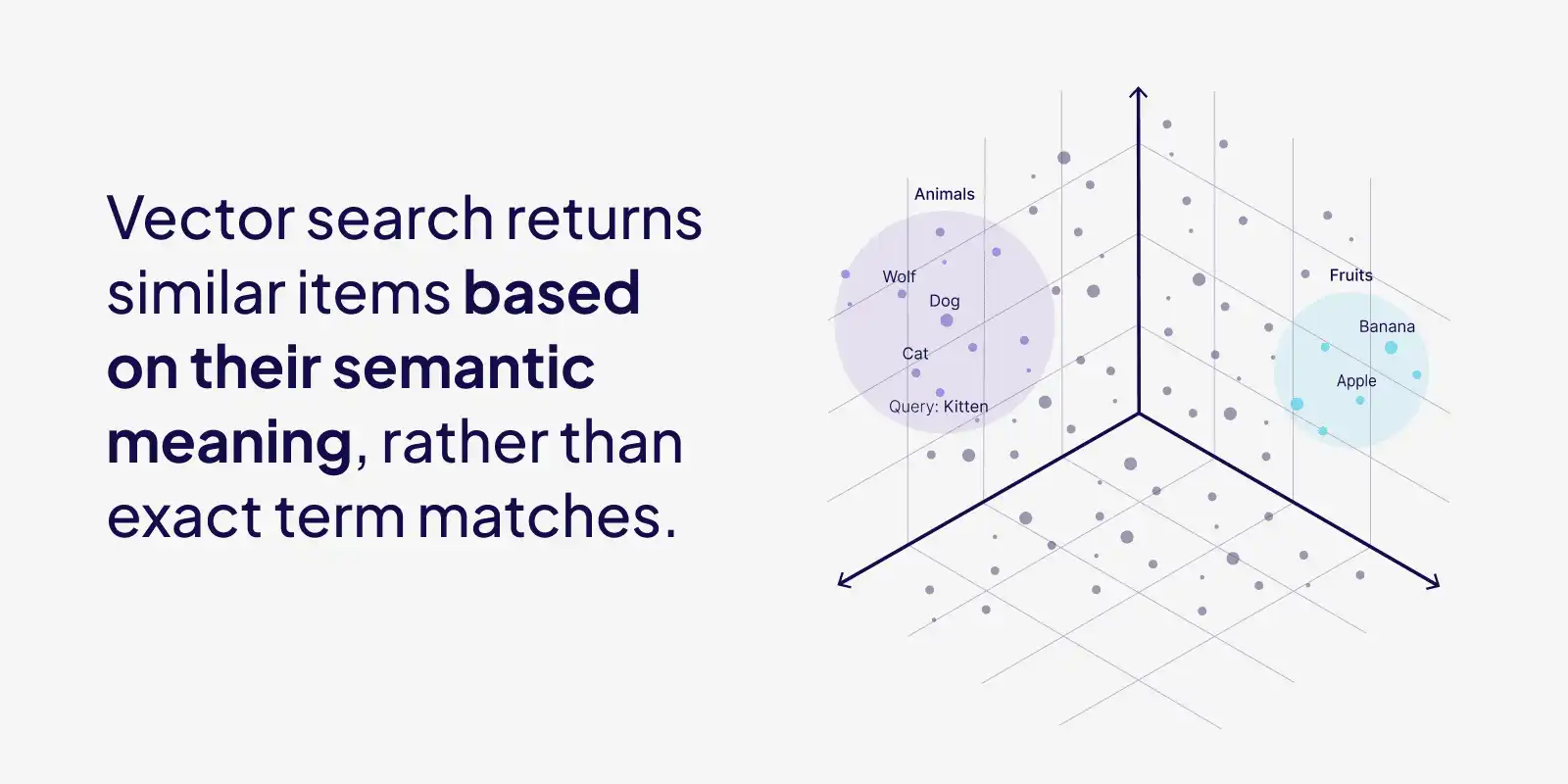
什么是向量检索?
向量检索的目标是:在给定一个查询向量的情况下,从向量集合中高效地找到最相似的结果。
原始的非结构化数据(如文本、图像、音频等)会先通过深度学习模型(如 BERT、ResNet 等)转化为固定维度的向量,这一过程称为 Embedding(嵌入)。随后,系统会在向量空间中计算这些向量之间的相似度(如余弦相似度、欧氏距离等),并返回与查询向量最为接近的结果,实现基于语义的智能检索。
与传统检索的区别
- 关键词检索:依赖字符串匹配,难以理解深层语义。
- 向量检索:基于语义相似度,能够发现“意思相近”但表达不同的内容。
应用场景
向量检索已成为现代智能系统中的关键组件,典型应用包括:
- 🖼 图像检索:以图搜图、以视频帧找相似素材;
- 💬 语义搜索:句子/文档的语义级相似搜索;
- 🧠 RAG(Retrieval-Augmented Generation):大语言模型调用向量库提供上下文;
- 🎵 音频检索:哼唱识别、音乐指纹匹配;
- 🤝 推荐系统:基于 embedding 的召回阶段;
- 📚 多模态匹配:图文对齐、跨模态搜索。
相似度度量方式
在向量检索中,判断两个向量的相似性主要依赖于相似度或距离的计算。常见的度量方式包括:
余弦相似度(Cosine)
余弦相似度通过计算两个向量夹角的余弦值来衡量它们在方向上的相似性。
其取值范围为 [-1, 1],越接近 1 表示越相似。余弦相似度常用于语义搜索和推荐系统等需要方向相关性的任务。
Tip
在某些系统中,为了将余弦相似度转化为距离形式,通常会使用:
这种转换将结果归一化为 [0, 2] 区间,其中 0 表示完全相同,值越大表示越不相似。这种形式便于与其他距离度量(如 L2)统一处理。
欧氏距离(L2)
欧氏距离衡量两个向量在空间中的“直线距离”,是最常用的距离度量之一。
其取值范围为 [0, +∞),值越小表示两个向量越接近。欧氏距离特别适用于数值空间有实际几何意义的场景,如图像特征检索和用户行为分析。
Tip
在实际工程中,为了加速计算或简化排序过程,有些向量库(如 Faiss)会使用 平方欧氏距离(即去掉根号):
这种处理不会影响最近邻排序结果,但能显著减少计算开销。
内积(Inner Product, IP)
内积是向量之间最基本的运算之一,用于衡量它们在所有维度上的加权重叠程度:
内积的值大小与两个向量方向的相似性和模长有关。常用于向量未归一化、且特征强度(如得分、置信度)具有实际意义的场景。
Tip
在实际应用中,向量通常会先进行归一化处理(单位化),此时余弦相似度可简化为内积的形式:
因此,在许多向量数据库(如 Faiss、Milvus)中,使用内积代替余弦相似度是一种常见优化策略,可以提升计算效率。
此外,若向量未归一化,可直接使用 最大内积搜索(Max Inner Product Search, MIPS),这在推荐排序、评分预测等场景中尤为常见。
⚠️ 注意:内积本质上不是严格意义上的“距离度量”,它不满足非负性、对称性等性质,但在检索排序中仍非常有效。
为什么需要索引?
虽然暴力搜索(遍历所有向量并计算相似度)在理论上可以获取精确结果,但它在实际中计算代价极高,尤其是当向量数量达到百万甚至十亿时。
索引的意义:
- 降低搜索时间复杂度(从 O(n) 降到接近常数级);
- 降低内存消耗(通过压缩);
- 支持近似搜索(ANN)以在速度和精度之间取得平衡。
向量索引技术概览
向量索引方法可分为以下几类,每类都有不同的加速策略:
| 索引类型 | 代表方法 | 特点 |
|---|---|---|
| 树结构 | KD-Tree、Ball Tree | 精确度高,适用于低维小规模数据 |
| 哈希结构 | LSH、SQ、PQ | 构建快、速度快、适合高维稀疏检索 |
| 图结构 | HNSW、KGraph | 检索速度非常快,适合大规模高维数据 |
| 混合结构 | IVF-PQ、HNSW+PQ | 实践中常用,兼顾速度、精度与内存占用 |
每种索引技术在 精度、速度、构建成本、内存占用 等方面存在权衡,应根据具体业务场景选择。