Locality-Sensitive Hashing (LSH)
📖 本文参考整理自 Pinecone 官方博客:Locality Sensitive Hashing (LSH): The Illustrated Guide
Locality-Sensitive Hashing (LSH) 是一种经典的近似最近邻(Approximate Nearest Neighbor, ANN)检索方法。它能够以 远快于线性复杂度的方式,在大规模数据集中快速查找相似项,是实现高效向量搜索的核心技术之一。
✨ 为什么需要近似搜索?
在现实中,许多任务依赖于“相似性搜索”,例如:
- 🎧 Spotify 推荐你可能喜欢的歌曲
- 🛒 亚马逊根据购买记录推荐新商品
- 🌐 Google 搜索根据你输入的查询词匹配网页
- 📺 Netflix 为你推荐新剧集
这些应用背后都依赖于一个共同的操作:找到最相似的内容项(文档、用户、商品等)。
在数据规模极大的情况下(百万级甚至十亿级),暴力比对的代价极高:
- 计算所有向量对的相似度:复杂度为 \( O(n^2) \)
- 即使是给定一个查询向量,线性扫描也需要 \( O(n) \)
- 高维向量之间的相似度计算成本更高
因此,我们需要 近似搜索(Approximate Search),即只比较可能相关的向量子集,用少量计算换取略微的精度损失。
🧠 什么是 LSH?
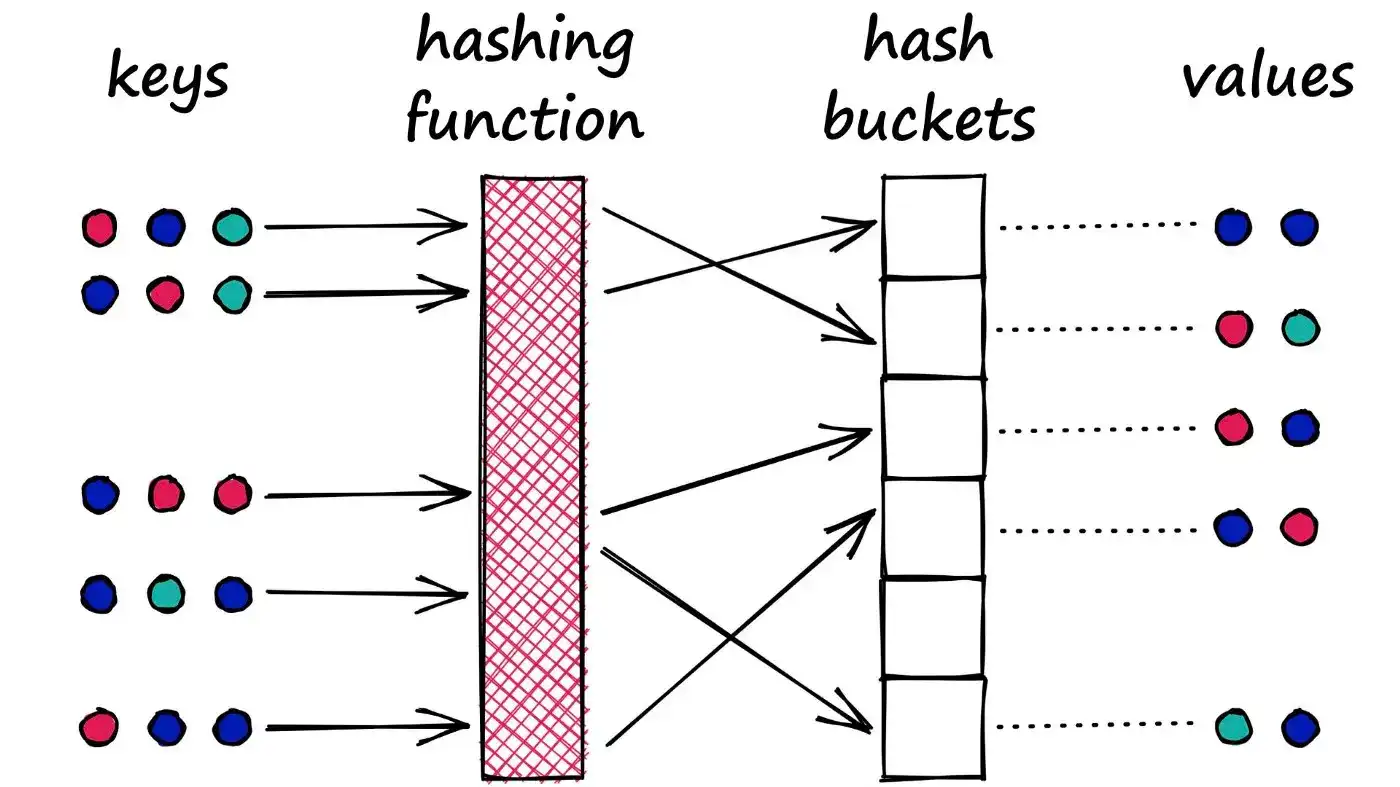
LSH(局部敏感哈希) 是一种能够实现子线性时间搜索的算法。其核心思想依赖于构造一种“局部敏感(Locality Sensitive)”的哈希函数族,使得:
- 相似的向量以较高概率被哈希到同一个桶中
- 不相似的向量以较低概率被哈希到同一个桶中
这样,我们只需在同桶中进行精确比较,从而极大减少计算量。
Tip
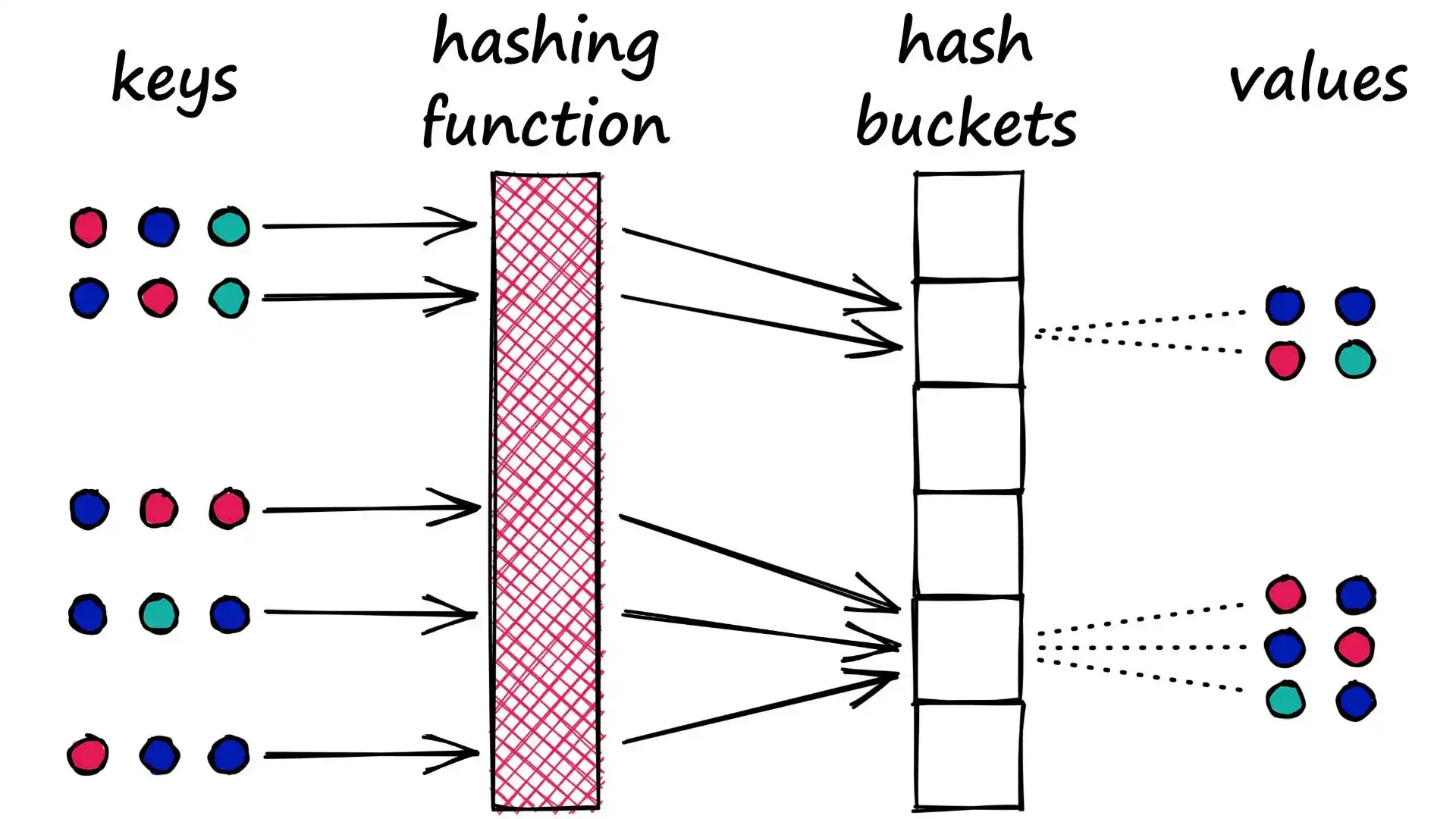
你可以将其理解为与 Python 字典类似的结构,不同之处在于:
- 传统哈希(如 dict):
- 避免冲突
- 不同值落入不同桶
- LSH 哈希:
- 鼓励“有意义的”冲突
- 相似值倾向落入同一桶
📦 LSH 的经典流程
在本文中,我们采用一种经典的 LSH 实现方案,包括以下三步:
- Shingling:将文档转化为 token 集合(如 k-gram)
- MinHashing:压缩集合为固定长度签名向量
- Banding:将签名向量分段哈希,找出候选相似对
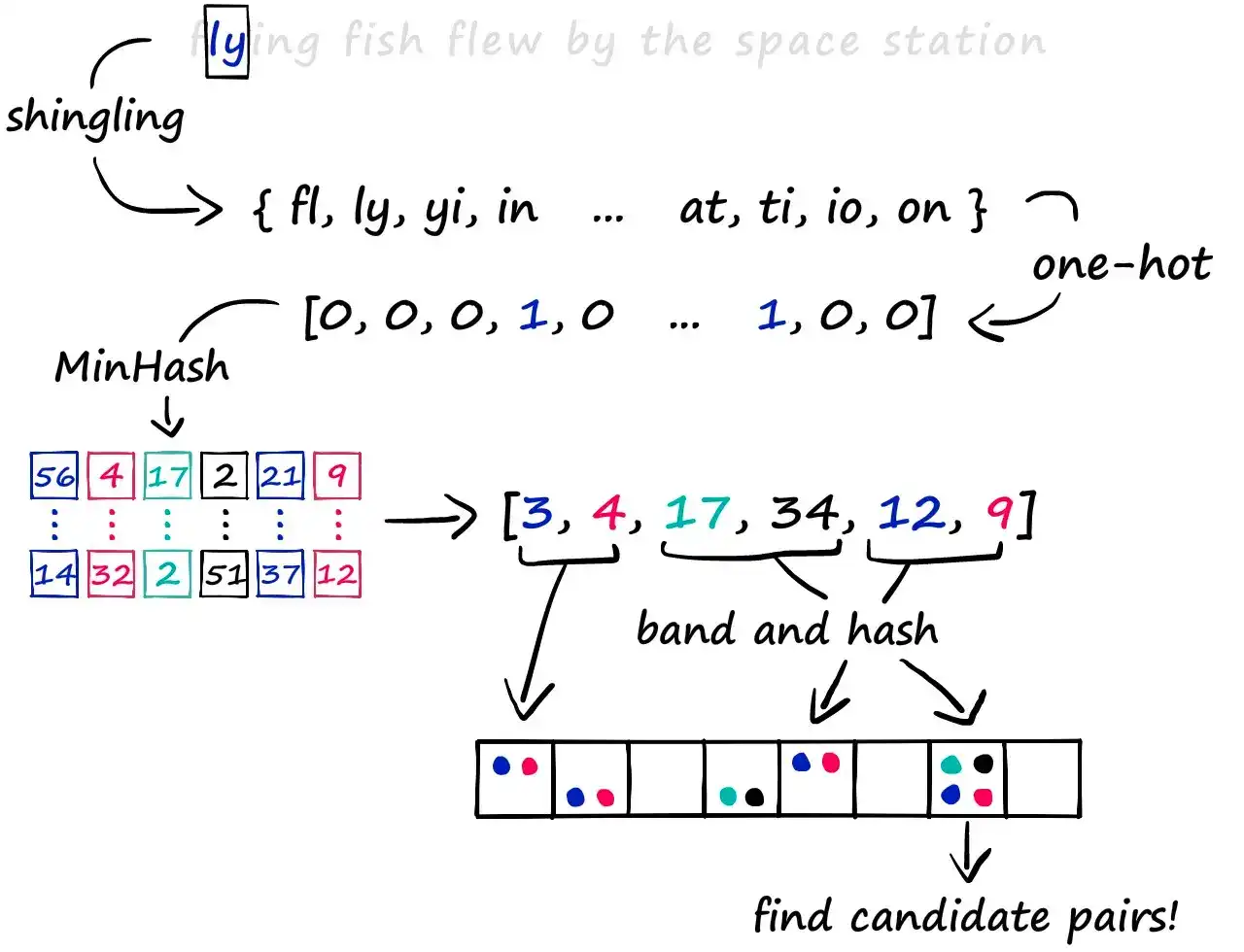
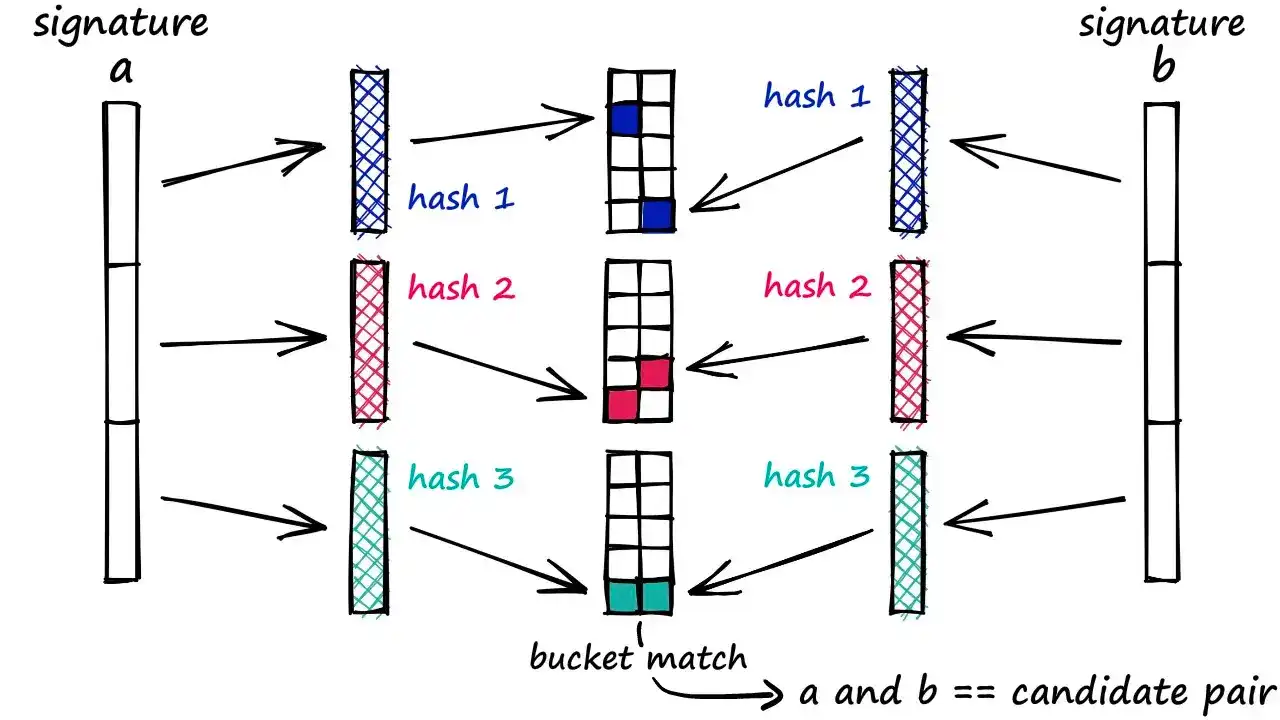
只要两个向量在至少一个段中哈希值相同,即认为它们是 候选对(Candidate Pairs),再做后续相似度精算。
Tip
虽然本文主要介绍传统的 MinHash + Banding 方法,但还有其他变体(如 Random Projection、SimHash 等),适用于不同距离度量和任务场景。
🔹 k-Shingling:字符串转集合
k-Shingling 是将文本字符串转化为“子串集合”的过程。其本质是使用一个长度为 \( k \) 的滑动窗口,在字符串上逐步滑动,并记录每一步所覆盖的子串 —— 我们称之为 shingle。

最终得到的是一个 去重后的 k-gram 集合(即集合的所有元素是长度为 k 的子字符串)。
a = "flying fish flew by the space station"
b = "we will not allow you to bring your pet armadillo along"
c = "he figured a few sticks of dynamite were easier than a fishing pole to catch fish"
def shingle(text: str, k: int):
shingle_set = []
for i in range(len(text) - k + 1):
shingle_set.append(text[i:i+k])
return set(shingle_set)
k = 2
a = shingle(a, k)
b = shingle(b, k)
c = shingle(c, k)
print(a)
# {'st', 'ac', 'w ', 'by', ' s', 'sh', ' f', 'g ', 'is', 'le', 'h ', 'e ', 'on', ' t', 'he', 'ti', 'y ', 'fl', 'ta', 'th', 'ce', 'ew', 'pa', 'fi', ' b', 'yi', 'at', 'io', 'in', 'ng', 'sp', 'ly'}
💡 为什么使用 Shingling?
- 相似的文本通常拥有较多重复的 shingles;
- 一个小的局部修改(如一个字或词)仅影响附近的少量 shingles;
- 对于段落的重排序也不会完全破坏 shingles 分布。
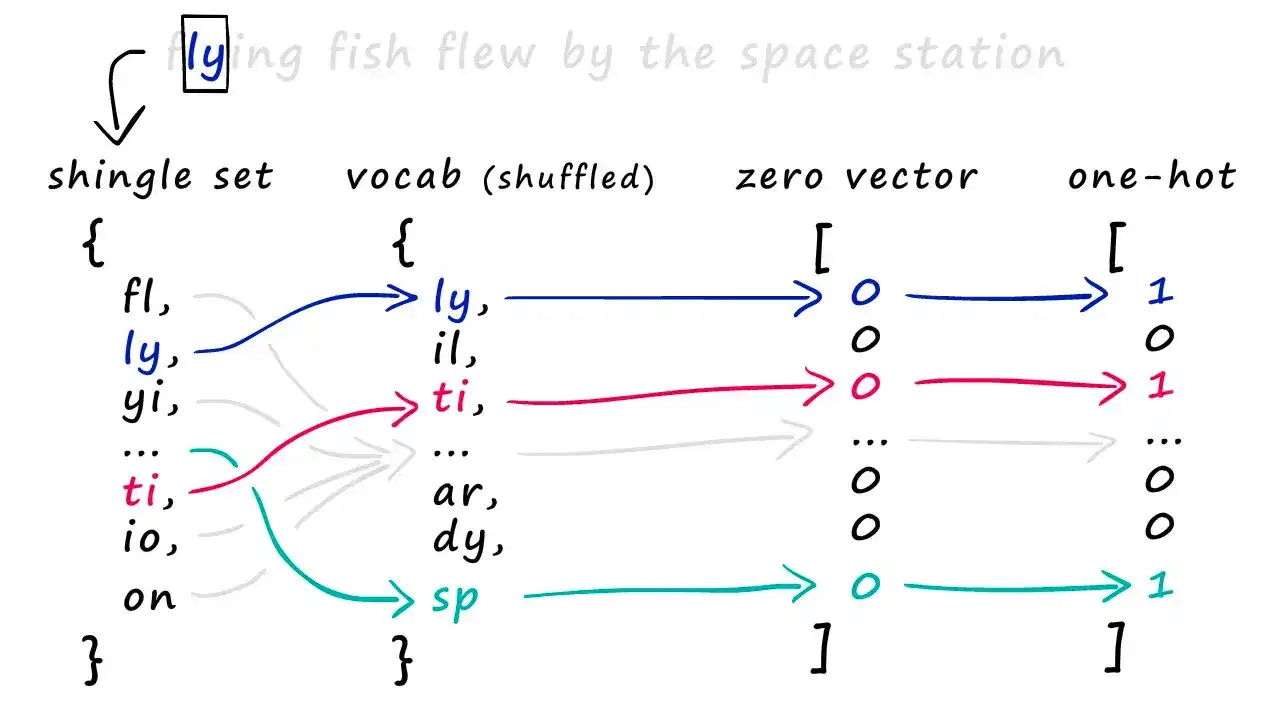
🔸 构建稀疏向量(one-hot encoding)
接下来,我们将每个文档的 shingles 集合转化为稀疏向量。
步骤如下:
-
构建总词表(vocab):将所有 shingles 集合合并为一个大集合,作为全集(所有可能出现的 token)
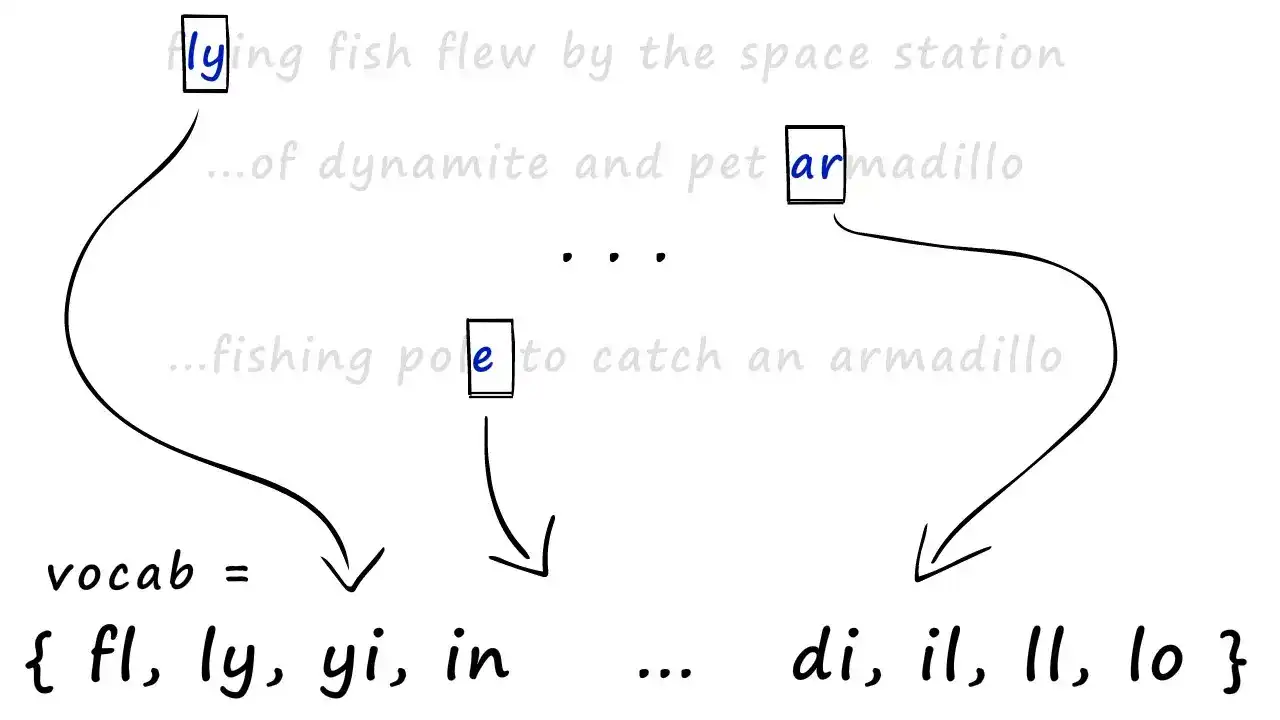
-
生成稀疏向量:为每个文档创建一个与词汇表大小相同的全 0 向量,并在 shingle 出现的位置标记为 1,这与 one-hot 编码 的思想类似。
Note
实际代码中我们通常使用一个 shingle -> index 的映射字典,方便将 shingles 映射到 vocab 中对应位置。
🔹 MinHashing:稀疏向量压缩为签名向量
在上一节中我们通过 k-Shingling 将文本转化为稀疏的 one-hot 向量。现在,我们使用 MinHashing 将这些高维稀疏向量压缩为短小的签名向量(dense vector),同时尽量保留集合之间的 Jaccard 相似性。
Note
注意:虽然我们在实现中以 one-hot 向量形式表示集合,但 MinHash 实质上是对“集合”的操作,其目标是近似计算集合间的 Jaccard 相似度。
💡 什么是 MinHash?
MinHash 的核心思想是:使用若干个“随机排列”作为 Hash 函数,对 one-hot 向量做转换,每个签名位置的值,取的是排列中第一个出现在 1 的位置上的索引。

下面是一个简单的示例,展示了如何使用 MinHash 对一个 one-hot 向量进行压缩。
from random import shuffle
vocab = ["a", "b", "c", "d", "e", "f"]
a_1hot = [1, 0, 0, 1, 0, 1]
hash_ex = list(range(1, len(vocab)+1))
shuffle(hash_ex)
# 和上面 gif 中的排列一致
hash_ex = [2, 1, 3, 6, 4, 5]
print(hash_ex)
for i in range(1, len(vocab)+1):
idx = hash_ex.index(i)
signature_val = a_1hot[idx]
print(f"{i} -> {idx} -> {signature_val}")
if signature_val == 1:
print('match, signature is', i)
break
# [2, 1, 3, 6, 4, 5]
# 1 -> 1 -> 0
# 2 -> 0 -> 1
# match, signature is 2
🔸 构建签名向量
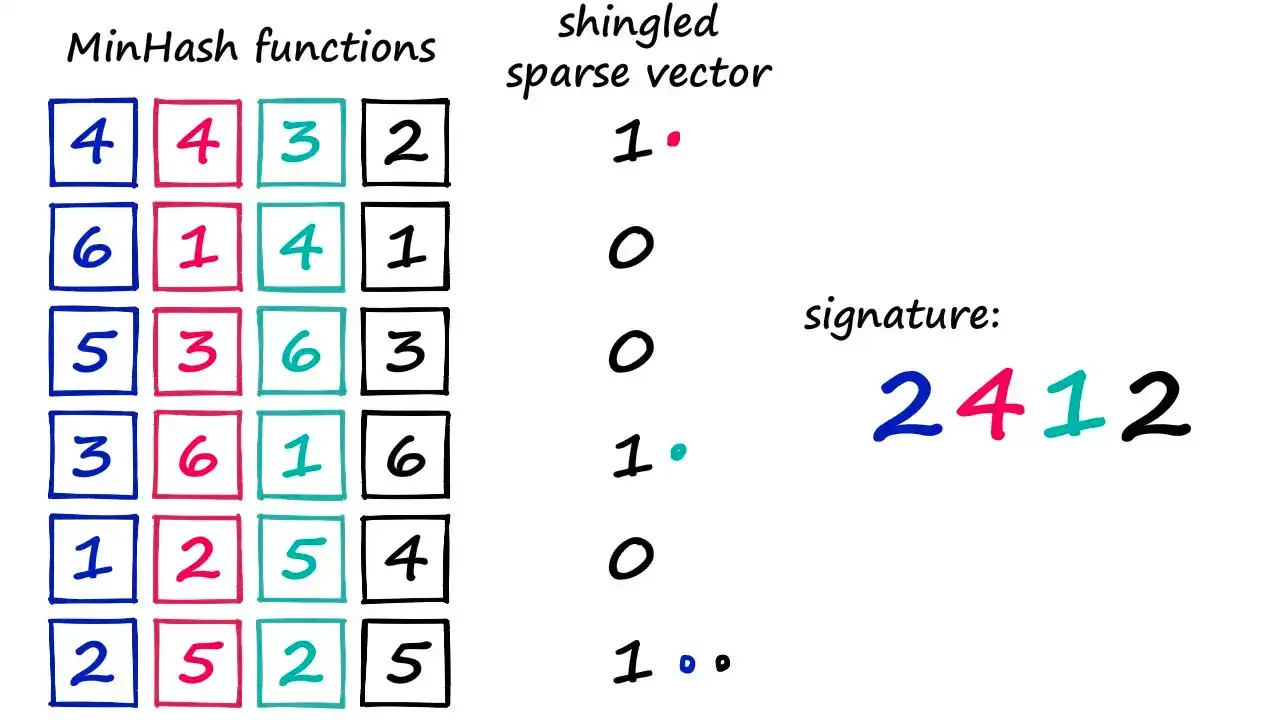
我们需要多个这样的函数(例如 4 个, 和图中保持一致),来得到一个 4 维的签名向量。
from random import shuffle
vocab = ["a", "b", "c", "d", "e", "f"]
def create_hash_func(size: int):
hash_ex = list(range(1, len(vocab)+1))
shuffle(hash_ex)
return hash_ex
def build_minhash_func(vocab_size: int, nbits: int):
hashes = []
for _ in range(nbits):
hashes.append(create_hash_func(vocab_size))
return hashes
# 创建 4 个 minhash 随机函数, 作为 MinHash functions
minhash_func = build_minhash_func(len(vocab), 4)
# 方便理解和验证, 使用固定的随机函数, 和图中保持一致
minhash_func = [
[4, 6, 5, 3, 1, 2],
[4, 1, 3, 6, 2, 5],
[3, 4, 6, 1, 5, 2],
[2, 1, 3, 6, 4, 5],
]
def create_hash(vector: list):
signature = []
for func in minhash_func:
for i in range(1, len(vocab)+1):
idx = func.index(i)
signature_val = vector[idx]
print(f"{i} -> {idx} -> {signature_val}")
if signature_val == 1:
# signature.append(idx)
signature.append(i)
break
return signature
a_1hot = [1, 0, 0, 1, 0, 1]
a_sig = create_hash(a_1hot)
print("a_sig: ", a_sig)
# 1 -> 4 -> 0
# 2 -> 5 -> 1
# 1 -> 1 -> 0
# 2 -> 4 -> 0
# 3 -> 2 -> 0
# 4 -> 0 -> 1
# 1 -> 3 -> 1
# 1 -> 1 -> 0
# 2 -> 0 -> 1
# a_sig: [2, 4, 1, 2]
MinHash 签名记录的是编号、哈希值,还是索引?
在 MinHash 中,签名值可以是:
- 原始集合中元素的 编号(如:行号或元素位置 i)
- 或者是 permutation 顺序中第一个命中集合的元素编号
✅ 实际上,签名值记录的是“谁最先被当前哈希函数命中”,至于是记录编号还是某种下标,并不重要。
最关键的是:
- 一致性:所有文档必须使用相同的 hash 函数和相同的签名生成规则;
- 等价性:两个集合在某个哈希函数下,如果最先命中的是同一个元素,那么它们这一位签名必须相同;
- 可比性:签名值应该具备语义可比性(例如编号或 hash 值),而不是 permutation 中的索引位置。
❗例如,在实现中:
signature.append(i):记录的是当前被命中的元素编号 ✅ 推荐(和图片中一致)signature.append(idx):记录的是该元素在 permutation 中的位置
🤝 只要以上条件满足,签名值选择哪种表示方式都无妨,它本质是在表达同一个事实:
“在这个哈希函数下,第一个命中的集合元素是谁。”
✅ 信息是否保留?从稀疏向量到签名的相似度验证
MinHash 的关键价值在于 压缩维度的同时,仍能保留集合之间的 Jaccard 相似性。为了验证这一点,我们对比:
- 原始 Shingles 的集合相似度
- MinHash 签名的集合相似度(以 set 的方式进行比较)
def jaccard(a: set, b: set):
return len(a.intersection(b)) / len(a.union(b))
# 原始 shingles vs 签名向量的 Jaccard 相似度
print(jaccard(a, b), jaccard(set(a_sig), set(b_sig)))
# (0.14814814814814814, 0.10344827586206896)
print(jaccard(a, c), jaccard(set(a_sig), set(c_sig)))
# (0.22093023255813954, 0.13793103448275862)
print(jaccard(b, c), jaccard(set(b_sig), set(c_sig)))
# (0.45652173913043476, 0.34615384615384615)
虽然签名向量的 Jaccard 相似度略低,但依然保留了原始集合的相对关系,说明压缩过程中的语义保持是有效的。
Note
如果你使用更多的哈希函数(例如签名长度增加至 100 或 200),MinHash 的近似程度会更高,与原始 Jaccard 相似度更加接近。
🧩 Band and Hash:LSH 的候选匹配过程
通过 MinHash,我们已经将每个文本转换为长度一致且数值范围为 1 到 len(vocab) 的签名向量。这些向量将作为我们输入 LSH 算法的基础。

在整体哈希签名向量时,难以判断两个签名的相似性,因为我们只需部分相同而非完全相同。整体哈希可能导致仅一位不同的签名被分配到不同的哈希桶中,无法成为候选对。为了解决这个问题,Banding 提供了一种机制,使得“部分相似”的签名可以被哈希到同一个桶中。
✂️ Banding 如何工作?
我们将签名向量划分为 b 个 Band,每个 Band 包含 r 个连续的值。接着,每个 Band 通过哈希函数映射到哈希桶。可以选择使用一个或多个哈希函数,将每个子向量映射到相应的哈希桶。
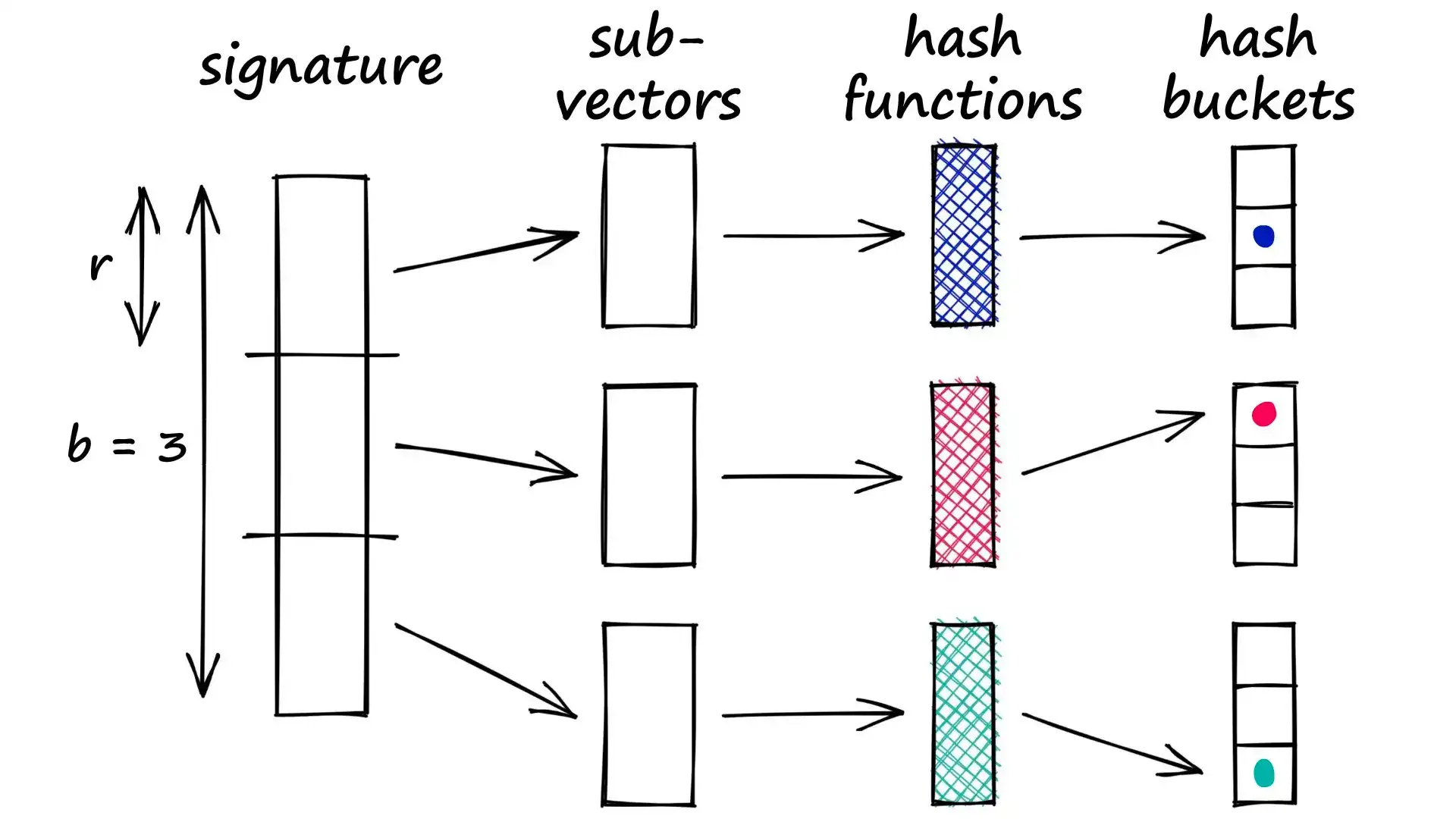
我们可以采用更灵活的策略:只要任意两个子向量碰撞,就将完整向量视为候选对。为此,将签名拆分为子向量,并使用相同的哈希函数处理。这样,部分匹配的向量被视为候选对,尽管可能增加误报,但我们会努力降低误报率。
🧮 LSH 总结与应用建议
LSH 提供了一种高效处理大规模相似性搜索的思路,尤其适用于:
- Jaccard 相似度(如文本集合)
- 欧几里得距离(通过其他变体,如 random projection)
- 海量向量集合中的初筛阶段(作为倒排索引替代方案)
⚠️ 但 LSH 也有其局限性:
- 对高维向量效果下降(curse of dimensionality)
- 难以应对动态插入删除
- 参数(band 数、签名长度等)需手动调优
在实际工程中,可将 LSH 与精确搜索/向量数据库结合使用,构建高效混合搜索系统。