Hierarchical Navigable Small Worlds (HNSW)
📖 本文参考整理自 Pinecone 博客 Hierarchical Navigable Small Worlds (HNSW)
HNSW(Hierarchical Navigable Small World)是一种基于图的向量索引算法,专为 高效的近似最近邻搜索(ANN) 而设计。它以 高召回率、低查询延迟 而著称,在 FAISS, Milvus 等主流向量数据库中广泛使用。

HNSW 基础知识
HNSW 构建了一种近邻图(Proximity Graph),每个顶点都代表一个向量。相邻顶点通过边相连,通常使用欧氏距离来评估向量之间的相似性。然而,HNSW 不仅仅是一个普通的近邻图。它的发展基于两个关键概念:
- 概率跳表(Probability Skip List)
- 可导航小世界图(Navigable Small World Graph)
概率跳表(Probability Skip List)
跳表由 William Pugh 于 1990 年首次提出,其设计目的是结合有序数组的查找速度与链表的插入效率。跳表通过多层链表结构实现高效搜索:
- 顶层链表具有最大的跳跃跨度,能够快速跨越大量节点;
- 随着层级下降,跳跃跨度逐渐减小,节点分布愈加密集。
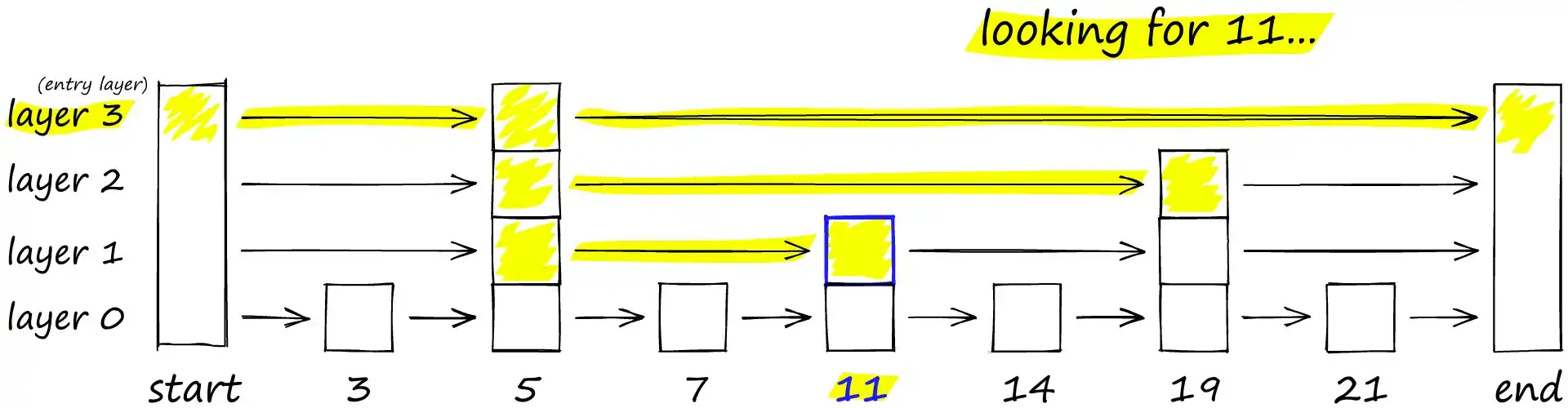
查找操作从顶层链表开始,沿着链表向右移动,直到超出目标值,然后向下切换到下一层,重复此过程,直至到达最底层。
Note
HNSW 采用了跳表的“层级与跳跃”结构设计:
- 在高层,连接较长且稀疏,旨在快速缩小搜索范围;
- 在低层,连接则更为密集,以实现高精度的近邻搜索。
Navigable Small World(NSW)
NSW 图是在 2011-2014 年多个论文中提出的一种近似最近邻搜索结构。它在普通近邻图的基础上,加入了长距离连接,使搜索复杂度接近对数级。
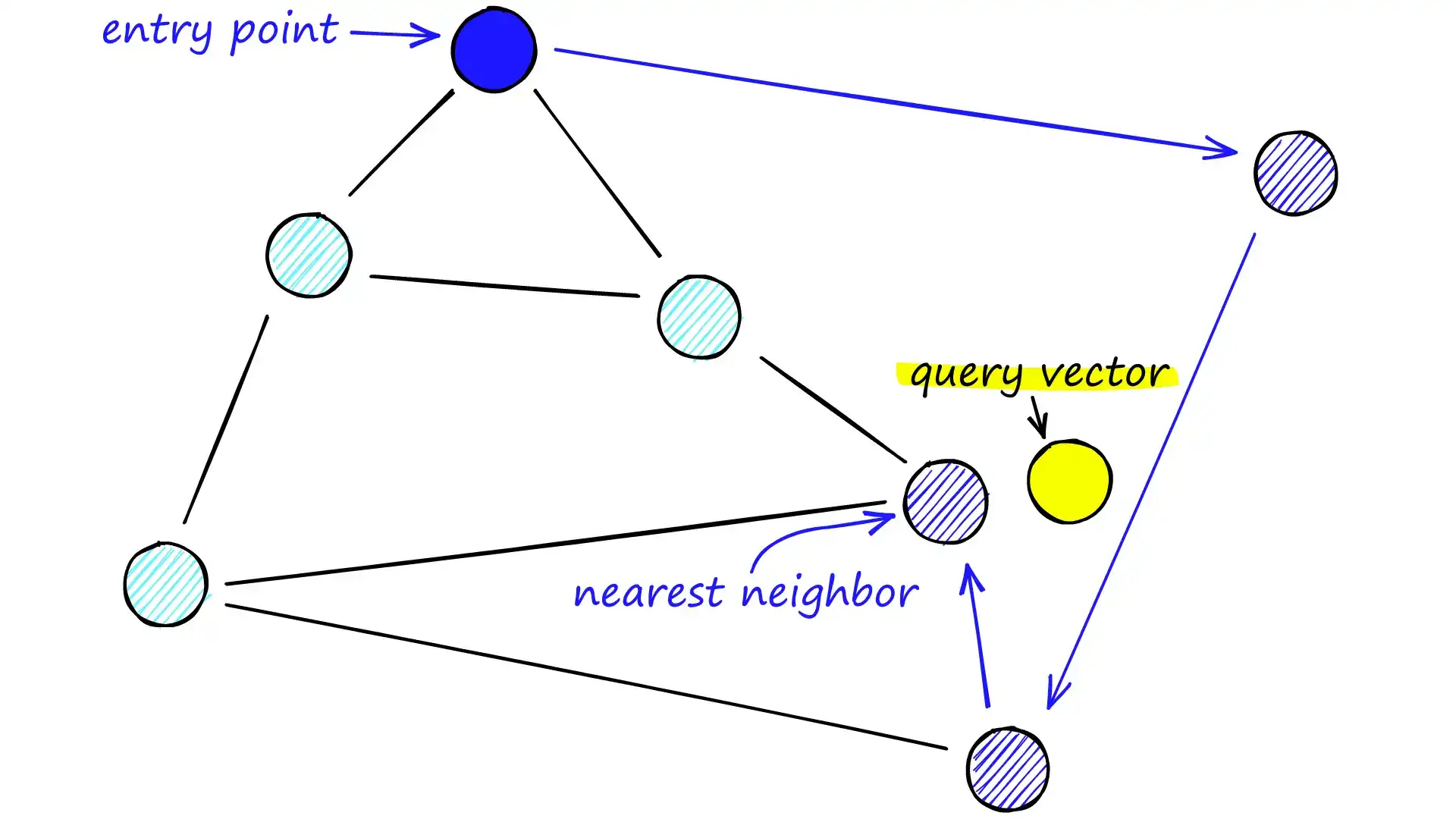
NSW 的基本构成
- 每个顶点连接若干“朋友”节点(邻居);
- 起始搜索从预定义的入口点开始;
- 算法贪婪地向更接近查询向量的邻居跳转,直到达到局部最优。
Warning
这种贪婪路由方式非常高效,但也可能陷入局部最小值,提前停止搜索。值得注意的是,只有当图具备“可导航性(navigability)”时,贪婪路由才能实现对数级的搜索效率。当图中节点数量较大(例如 1 万以上)而结构又不够均衡或连通性差时,贪婪搜索的效率会显著下降。
Zoom-Out vs Zoom-In
搜索路径可以划分为两个阶段:
- Zoom-Out 阶段:初始从 低度数(连接少) 节点出发,由于连接稀疏,很可能在尚未接近目标向量之前就陷入局部最优。这种情况下搜索容易过早终止,影响召回率;
- Zoom-In 阶段:逐渐过渡到 高度数(连接多) 节点。这些节点拥有更丰富的连接,能更精确地靠近目标向量,提升搜索准确性。
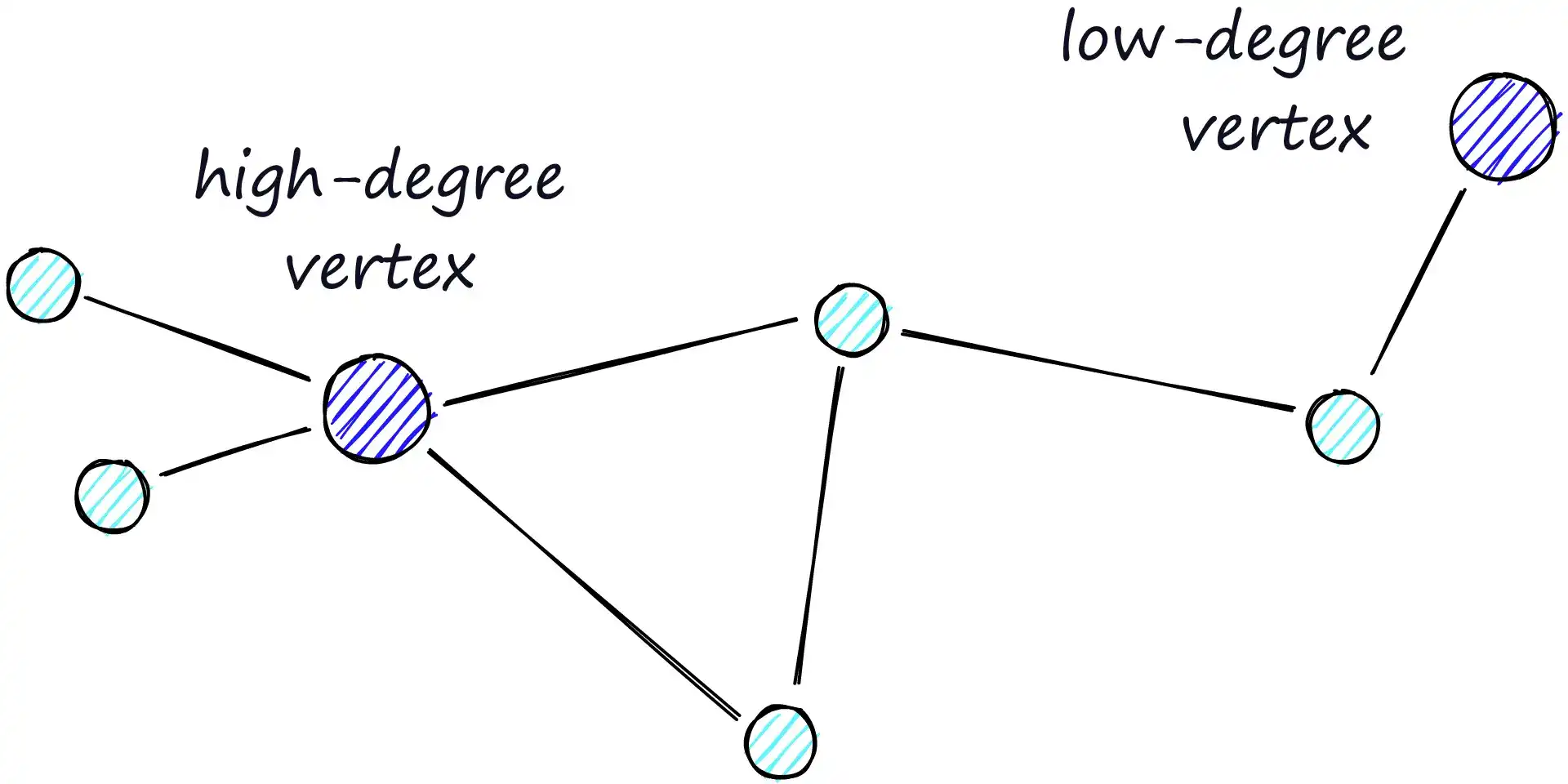
每个节点的“度”(degree)即其边的数量,是决定图结构复杂度与搜索质量的关键因素。
Note
为了提高召回率、减少早停的可能性,可以通过增加图中节点的平均连接数来提升整体连通性。然而,这样会显著增加图的构建成本与查询开销,因此需在召回与性能之间权衡。
另一种方式是从图中高连接度节点作为起点(即从 zoom-in 阶段开始),这在低维数据中能显著提升效果。这一思路也深深影响了 HNSW 的设计。
HNSW 的构建
HNSW 是 NSW 的自然进化版本,结合了 Pugh 概率跳表的分层多级思想。在 NSW 中引入层级结构后,图的连接被分布在不同层级:
- 顶层:仅包含最长的连接,用于快速跨越远距离节点;
- 底层:包含最短且最密集的连接,实现高精度的局部搜索。
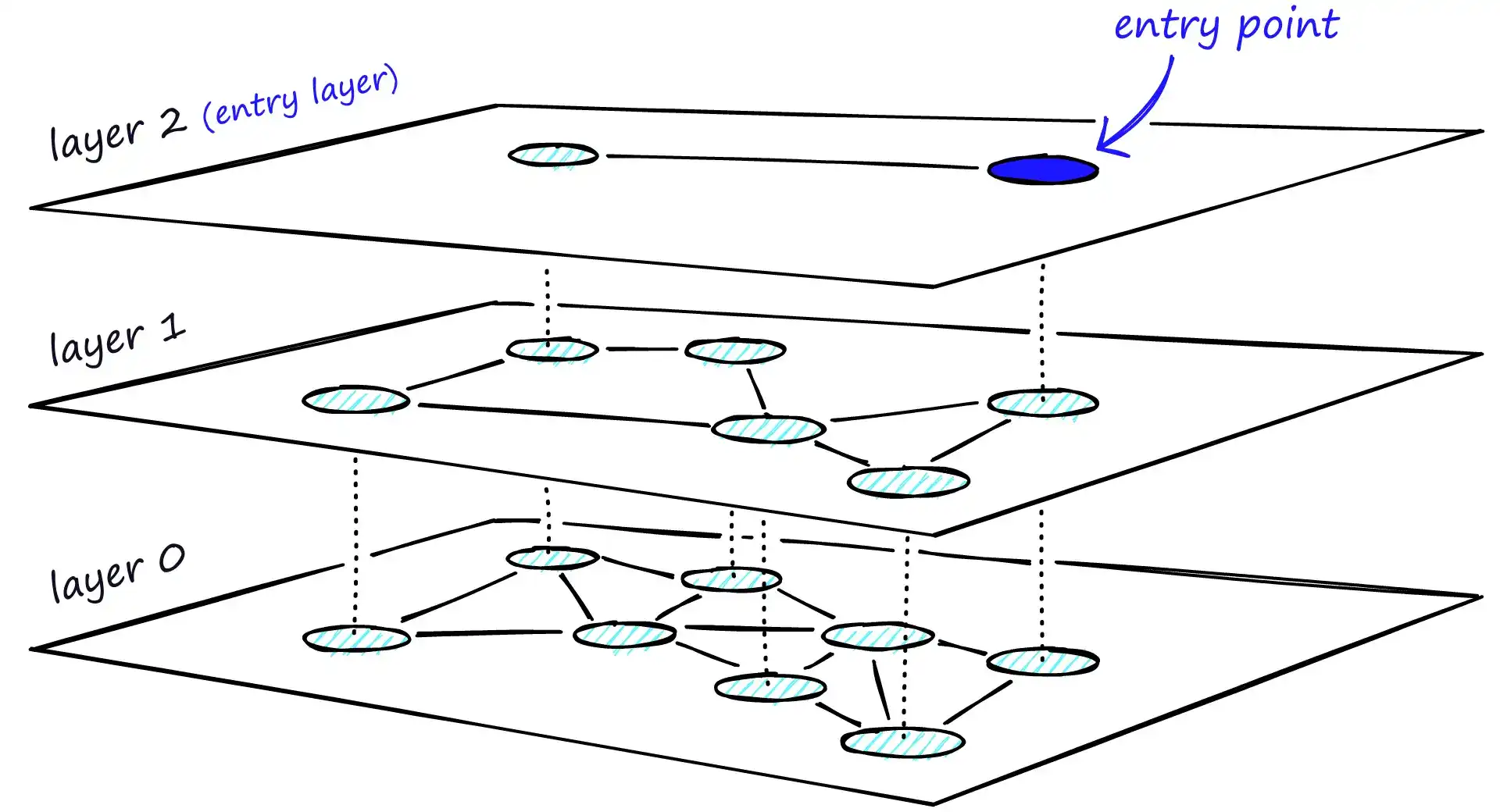
这种分层图的顶层作为全局入口点,节点数量少且连接跨度大,方便快速定位到接近目标区域的节点。随着搜索逐层向下,连接长度逐渐缩短、数量增多,从而细化搜索过程。
搜索过程:
- 进入顶层:从固定入口点出发,遍历长连接以接近查询向量。顶层节点往往是高度数节点(连接跨多层),这意味着搜索默认从 NSW 的 Zoom-In 阶段开始,有助于避免早停;
- 贪婪遍历:在当前层中,重复贪婪选择距离更近的邻居,直到无法找到更近的节点;
- 层级下降:到达当前层的局部最优后,移动到相同节点在下一层的位置继续搜索;
- 底层精细化:在最底层完成最后的贪婪搜索,输出最终最近邻结果。
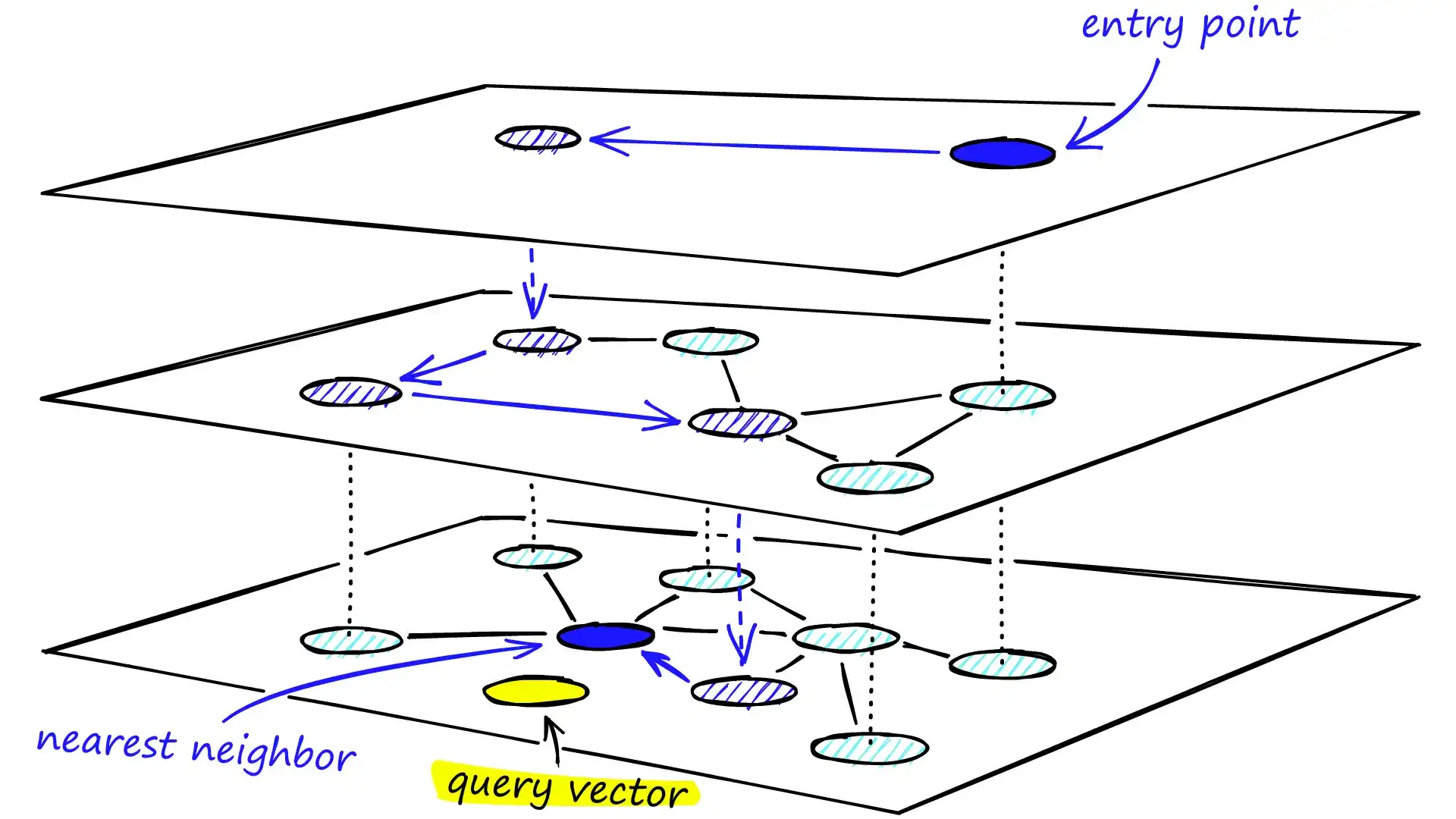
这种逐层下钻的搜索方式兼顾了全局跳跃和局部精细搜索,实现了高效率与高精度的平衡。
图构建(Graph Construction)
HNSW 图是通过逐个插入向量构建的,构建过程中需要确定每个向量将被放置在哪些层中。
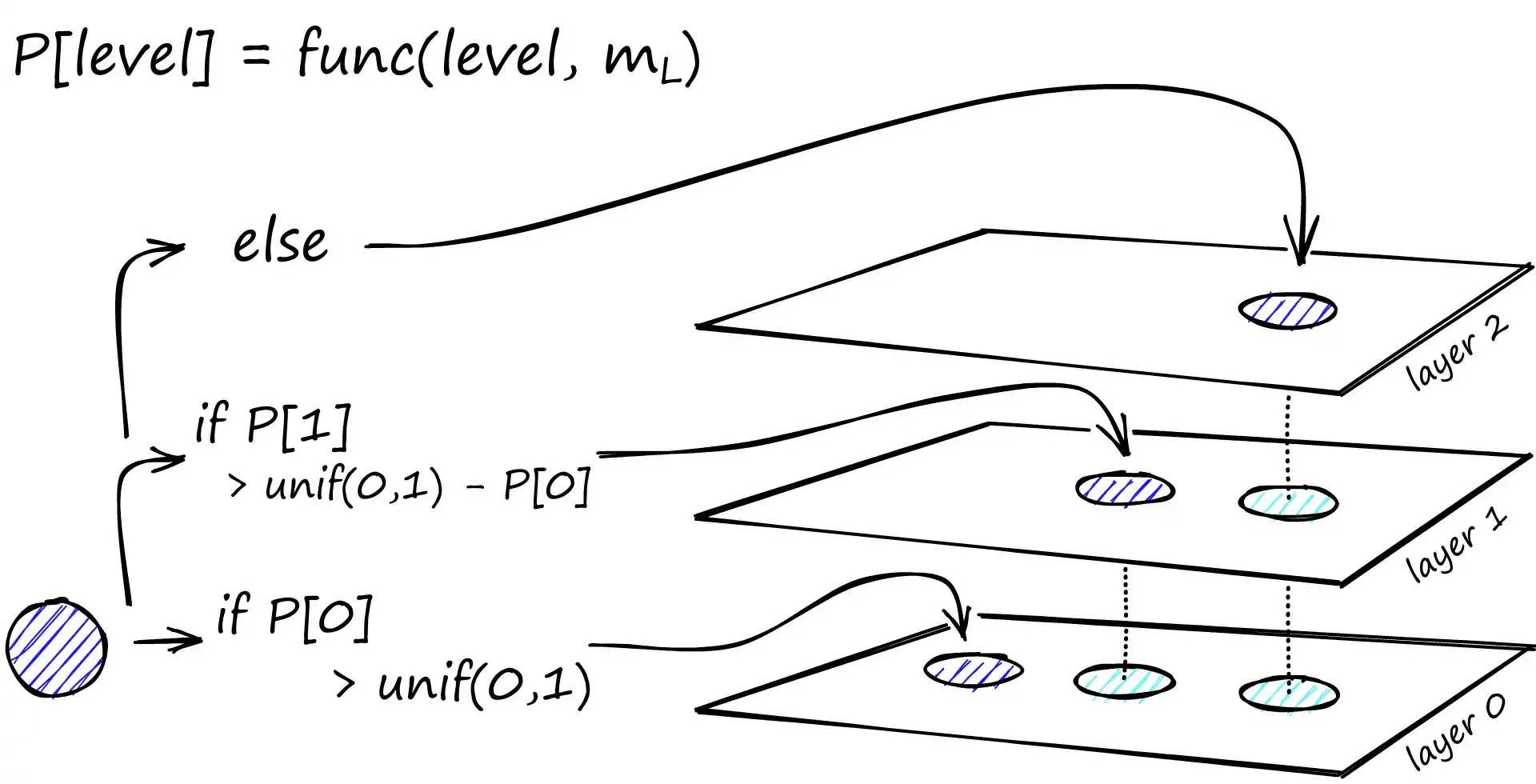
层数与概率分布
- 图的最大层数由参数 L 决定;
- 向量被插入到某一层的概率由一个与 层级乘数(level multiplier)
m_L相关的概率函数决定; - 当
m_L≈ 0 时,几乎所有向量都只会出现在第 0 层; - 对每个层(除第 0 层)重复概率判定,向量会被加入到其插入层以及所有更低的层中。
Tip
经验法则:m_L = 1 / ln(M) 可在减少跨层邻居重复度和搜索代价之间取得平衡。
构建流程
- 从顶层开始:以
ef = 1进行贪婪搜索,找到插入向量 q 在当前层的局部最优位置; - 逐层下降:在每一层重复贪婪搜索过程,直到到达插入层;
- 到达插入层后,将
ef提升至efConstruction(构建阶段参数),以返回更多近邻候选; - 建立连接:从候选中选择
M个最近邻作为新节点的连接,同时这些邻居也可作为下一层的入口点; - 连接数量限制:
M_max:限制非第 0 层节点的最大连接数;M_max0:限制第 0 层节点的最大连接数。
- 停止条件:插入在第 0 层达到局部最优时结束,完成新节点的加入。
这种 分层插入 + 控制连接数 的方式,使 HNSW 能够保持高效的可导航性和较低的搜索复杂度。
构建流程示例
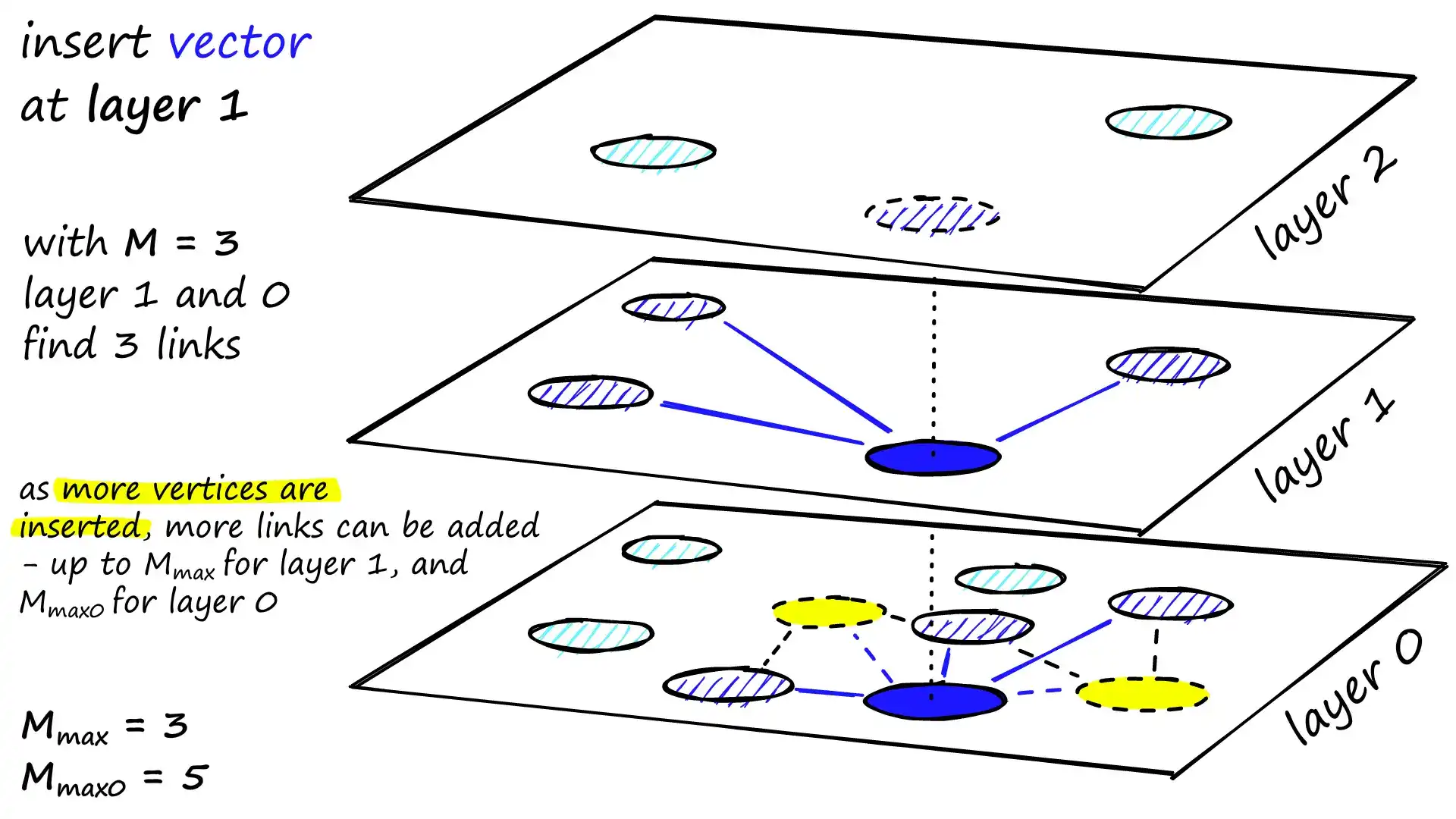
上图展示了 HNSW 插入新向量 的完整过程,可以分为以下几个阶段:
-
确定最高层级
- 通过概率函数(基于
m_L与unif(0,1)抽样)决定新向量 q 的最高层级。 - 例如图中
insert vector at layer 1表示 q 最高进入 layer 1,因此会被插入 layer 1 和 layer 0,而不会出现在 layer 2。
- 通过概率函数(基于
-
Phase 1 — 导航到插入层(仅定位,不建边)
- 从当前索引的最高层入口点(layer 2)开始,以
ef=1进行贪婪搜索,找到距离 q 最近的节点。 - 层层下降,直到到达插入层(layer 1),此阶段不建立任何连接,仅确定入口位置。
- 从当前索引的最高层入口点(layer 2)开始,以
-
Phase 2 — 从插入层到底层建立连接
- Layer 1:
- 从入口点出发,使用
efConstruction搜索候选邻居。 - 根据邻居选择策略(如最近距离、多样性启发式)选出最多
M=3个邻居。 - 与这些邻居双向连边。
- 将最近的一个邻居作为下一层(layer 0)的入口点。
- 从入口点出发,使用
- Layer 0:
- 重复候选搜索与邻居选择步骤。
- 度数上限使用
M_max0=5,允许底层图更密集以提升精度。
- Layer 1:
-
度数控制与后续增长
- 插入为双向连接,后续节点的插入也可能增加 q 的度数。
- 每层有最大度限制:
- 上层:
M_max = 3 - 底层:
M_max0 = 5
- 上层:
- 超出上限时,采用 修剪策略(通常是多样性启发式)移除部分边。
-
关键要点
- Phase 1:自顶向下定位插入位置(不建边)。
- Phase 2:从插入层逐层向下建立邻居连接。
- 控制参数:
M→ 每层目标邻居数M_max / M_max0→ 最大允许连接数efConstruction→ 构建时候选池大小,影响索引质量与构建速度
总结
HNSW 在高 recall 和灵活调参上具有优势,但需要权衡 准确率、速度、内存:
M决定图密度与内存占用。efSearch决定搜索精度与速度。efConstruction决定建图精度,对大批量查询也可能影响搜索时间。
在生产环境中,可结合 PQ 和 IVF 等技术进行混合索引优化,或直接使用 Pinecone、OpenSearch 等托管方案。